
使用 Flux 转换数据
此页面记录了早期版本的 InfluxDB OSS。InfluxDB OSS v2 是最新的稳定版本。请参阅等效的 InfluxDB v2 文档: 使用 Flux 转换数据。
当从 InfluxDB 查询数据时,您通常需要以某种方式转换数据。常见的示例包括将数据聚合为平均值、下采样数据等。
本指南演示了如何使用 Flux 函数来转换您的数据。它将引导您创建一个 Flux 脚本,该脚本将数据划分为时间窗口,计算每个窗口中 _value 的平均值,并将平均值输出为新表。
重要的是要了解数据的“形状”如何通过每个操作发生变化。
查询数据
使用在上一个从 InfluxDB 查询数据指南中构建的查询,但更新范围以从最近一小时拉取数据
from(bucket:"telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
Flux 函数
Flux 提供了许多执行特定操作、转换和任务的函数。您还可以在 Flux 查询中创建自定义函数。函数在 Flux 函数文档中详细介绍。
从 InfluxDB 查询数据时,常用的一种函数是聚合函数。聚合函数获取表中的一组 _value,对其进行聚合,并将其转换为新值。
此示例使用 mean() 函数来计算时间窗口内值的平均值。
以下示例逐步介绍了窗口化和聚合数据所需的步骤,但有一个
aggregateWindow()辅助函数可以为您完成此操作。了解此过程中的步骤是有好处的。
窗口化您的数据
Flux 的 window() 函数根据时间值对记录进行分区。使用 every 参数为每个窗口定义时间长度。
日历月和年
every 支持所有有效的持续时间单位,包括日历月 (1mo) 和年 (1y)。
对于此示例,以五分钟间隔 (5m) 窗口化数据。
from(bucket:"telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
当数据被收集到时间窗口中时,每个窗口都作为其自身的表输出。可视化时,每个表都会被分配一个唯一的颜色。
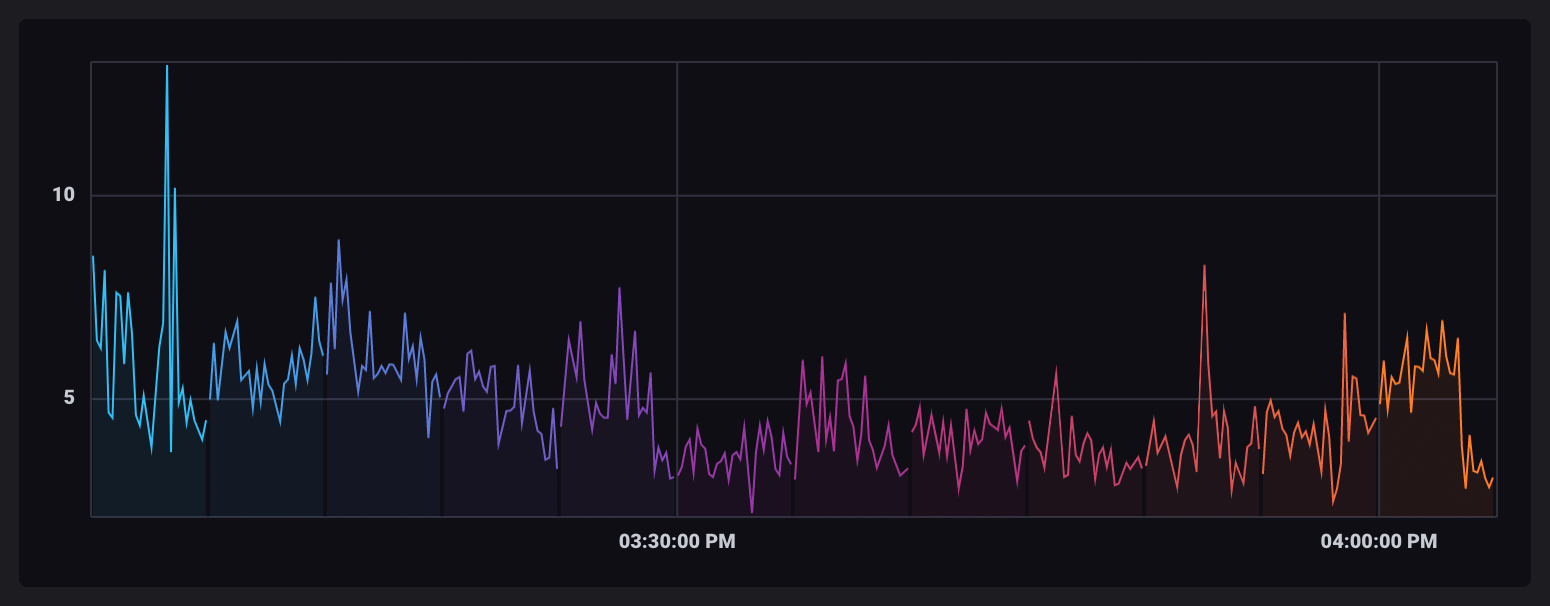
聚合窗口化数据
Flux 聚合函数获取每个表中的 _value,并以某种方式聚合它们。使用 mean() 函数来计算每个表的 _value 的平均值。
from(bucket:"telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
当每个窗口中的行被聚合时,它们的输出表仅包含一行,其中包含聚合值。窗口化表仍然是独立的,并且在可视化时,将显示为单个、未连接的点。
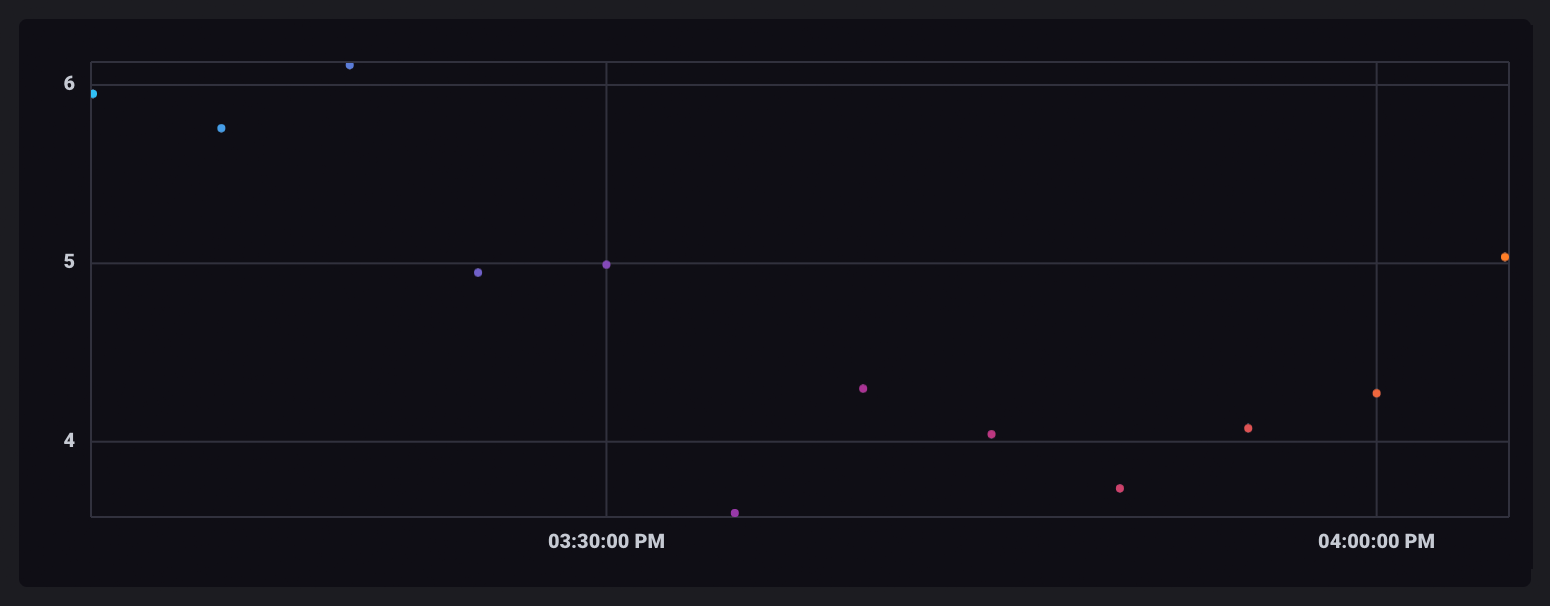
为您的聚合添加时间
当值被聚合时,结果表没有 _time 列,因为用于聚合的记录都具有不同的时间戳。聚合函数不会推断聚合值应使用哪个时间。因此,_time 列被删除。
下一步操作中需要 _time 列。要添加一个,请使用 duplicate() 函数将 _stop 列复制为每个窗口化表的 _time 列。
from(bucket:"telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
取消窗口化聚合表
使用 every: inf 参数的 window() 函数将所有点收集到单个无限窗口中。
from(bucket:"telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> window(every: 5m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)
一旦取消分组并合并到单个表中,聚合数据点将在您的可视化中显示为已连接。
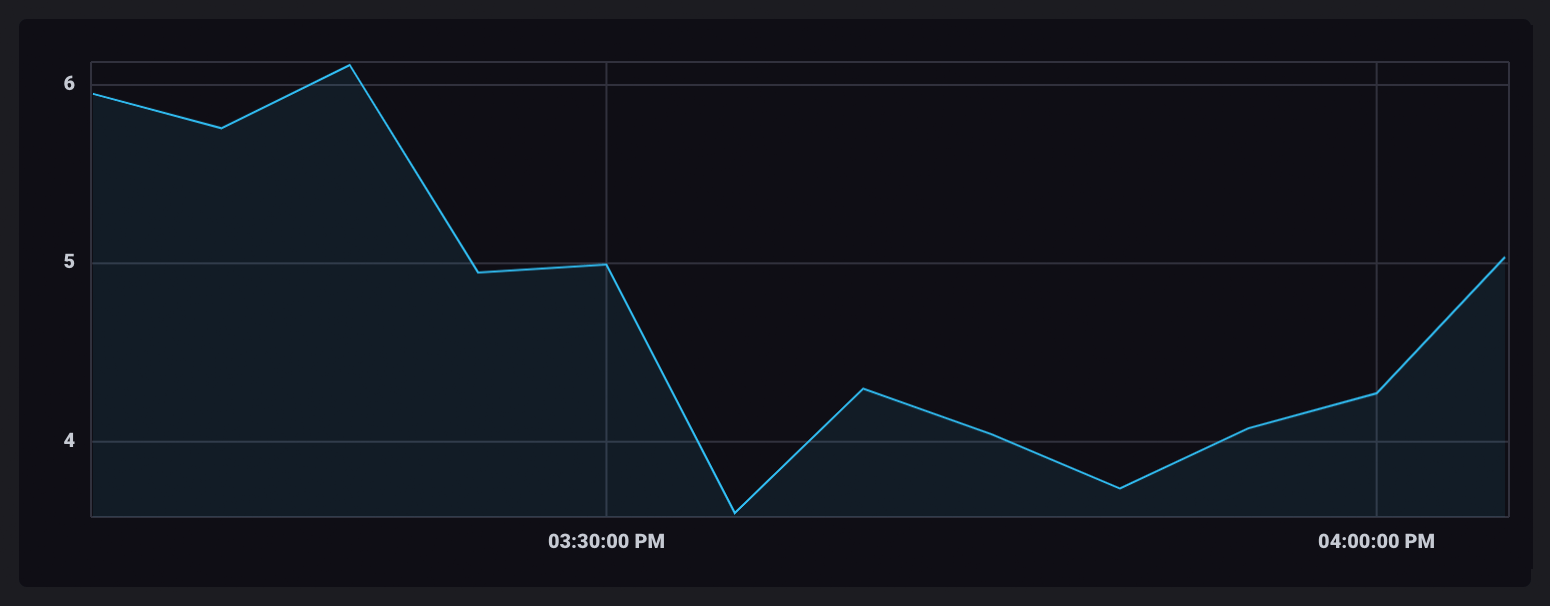
辅助函数
仅仅为了构建一个聚合数据的查询,这似乎需要大量的编码,但是,经历这个过程有助于理解数据在通过每个函数时如何改变“形状”。
Flux 提供(并允许您创建)“辅助”函数,这些函数抽象了许多这些步骤。使用 aggregateWindow() 函数可以完成本指南中执行的相同操作。
from(bucket:"telegraf/autogen")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r._field == "usage_system" and
r.cpu == "cpu-total"
)
|> aggregateWindow(every: 5m, fn: mean)
恭喜!
您现在已经构建了一个 Flux 查询,该查询使用 Flux 函数来转换您的数据。还有许多其他方法可以使用 Flux 的原始函数和您自己的自定义函数来操作您的数据,但这对于基本语法和查询结构来说是一个很好的介绍。
要更深入地了解窗口化和聚合数据,并查看每次转换的示例数据输出,请查看窗口化和聚合数据指南。
此页对您有帮助吗?
感谢您的反馈!