
监控 InfluxDB Enterprise 集群
InfluxDB Enterprise 提供高可用性和高度可扩展的集群解决方案,以满足您的时间序列数据需求。 使用 Chronograf 评估集群的健康状况并监控项目背后的基础设施。
本指南提供有关使用 Chronograf、InfluxDB 和 Telegraf 监控 InfluxDB Enterprise 集群中数据节点的逐步说明。
要求
您已拥有一个功能齐全且已启用身份验证的 InfluxDB Enterprise 集群。 有关详细设置说明,请参阅 InfluxDB Enterprise 文档。 本指南使用包含三个元节点和三个数据节点的 InfluxData Enterprise 集群;这些步骤也适用于其他集群配置。
InfluxData 建议使用单独的服务器来存储您的监控数据。 可以将监控数据存储在您的集群中,并将集群连接到 Chronograf,但通常情况下,您的监控数据应位于单独的服务器上。
您正在 Ubuntu 安装上工作。 TICK 栈的 Chronograf 和其他组件在多个操作系统和硬件架构上均受支持。 请查看下载页面以获取您选择的二进制文件的链接。
架构概述
在我们开始之前,以下是最终监控设置的概述

上图显示了一个 InfluxDB Enterprise 集群,该集群由三个元节点 (M) 和三个数据节点 (D) 组成。 每个数据节点都有自己的 Telegraf 实例 (T)。
每个 Telegraf 实例都配置为使用 Telegraf 系统统计信息输入插件收集节点 CPU、磁盘和内存数据。 Telegraf 实例还配置为将这些数据发送到位于单独服务器上的单个 InfluxDB OSS 实例。 当 Telegraf 将数据发送到 InfluxDB 时,它会自动使用相关数据节点的主机名标记数据。
存储 Telegraf 数据的 InfluxDB OSS 实例已连接到 Chronograf。 Chronograf 使用 Telegraf 数据中的主机名来填充主机列表页面,并在用户界面中提供其他特定于主机名的信息。
设置描述
InfluxDB OSS 设置
步骤 1:下载并安装 InfluxDB
可以从 InfluxData 下载页面下载 InfluxDB。
步骤 2:启用身份验证
出于安全目的,请在 InfluxDB 配置文件 (influxdb.conf) 中启用身份验证,该文件位于 /etc/influxdb/influxdb.conf 中。
在配置文件的 [http] 部分中,取消注释 auth-enabled 选项并将其设置为 true
[http]
# Determines whether HTTP endpoint is enabled.
# enabled = true
# The bind address used by the HTTP service.
# bind-address = ":8086"
# Determines whether HTTP authentication is enabled.
auth-enabled = true #💥
步骤 3:启动 InfluxDB
接下来,启动 InfluxDB 进程
~# sudo systemctl start influxdb
步骤 4:创建管理员用户
在您的 InfluxDB 实例上创建管理员用户。 因为您启用了身份验证,所以您必须在继续下一节之前执行此步骤。 运行以下命令以创建管理员用户,将 chronothan 和 supersecret 替换为您自己的用户名和密码。 请注意,密码需要单引号。
~# curl -XPOST "https://:8086/query" --data-urlencode "q=CREATE USER chronothan WITH PASSWORD 'supersecret' WITH ALL PRIVILEGES"
成功的 CREATE USER 查询返回空白结果
{"results":[{"statement_id":0}]} <--- Success!
Telegraf 设置
在集群中的每个数据节点上执行以下步骤。 您将在本节末尾返回到您的 InfluxDB 实例。
步骤 1:下载并安装 Telegraf
可以从 InfluxData 下载页面下载 Telegraf。
步骤 2:配置 Telegraf
配置 Telegraf 以将监控数据写入您的 InfluxDB OSS 实例。 Telegraf 配置文件位于 /etc/telegraf/telegraf.conf 中。
首先,在 [[outputs.influxdb]] 部分中,将 urls 选项设置为您的 InfluxDB OSS 实例的 IP 地址和端口。 InfluxDB 默认在端口 8086 上运行。 此步骤确保 Telegraf 将数据写入您的 InfluxDB OSS 实例。
[[outputs.influxdb]]
## The full HTTP or UDP endpoint URL for your InfluxDB instance.
## Multiple urls can be specified as part of the same cluster,
## this means that only ONE of the urls will be written to each interval.
# urls = ["udp://:8089"] # UDP endpoint example
urls = ["http://xxx.xx.xxx.xxx:8086"] #💥
接下来,在同一个 [[outputs.influxdb]] 部分中,取消注释并设置 username 和 password 选项,以设置为您在上一节中创建的用户名和密码。 Telegraf 必须知道您的用户名和密码才能成功将数据写入您的 InfluxDB OSS 实例。
[[outputs.influxdb]]
## The full HTTP or UDP endpoint URL for your InfluxDB instance.
## Multiple urls can be specified as part of the same cluster,
## this means that only ONE of the urls will be written to each interval.
# urls = ["udp://:8089"] # UDP endpoint example
urls = ["http://xxx.xx.xxx.xxx:8086"] # required
[...]
## Write timeout (for the InfluxDB client), formatted as a string.
## If not provided, will default to 5s. 0s means no timeout (not recommended).
timeout = "5s"
username = "chronothan" #💥
password = "supersecret" #💥
Telegraf System 输入插件 默认启用,无需额外配置。 输入插件自动收集有关系统负载、正常运行时间和已登录用户总数的一般统计信息。 启用的输入插件在配置文件的 INPUT PLUGINS 部分中配置;例如,以下是控制 CPU 数据收集的部分
###############################################################################
# INPUT PLUGINS #
###############################################################################
# Read metrics about cpu usage
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## If true, collect raw CPU time metrics.
collect_cpu_time = false
步骤 3:重启 Telegraf 服务
重启 Telegraf 服务,以使您的配置更改生效
macOS
telegraf --config telegraf.conf
Linux (sysvinit 和 upstart 安装)
sudo service telegraf restart
Linux (systemd 安装)
systemctl restart telegraf
对集群中的每个数据节点重复步骤一到四。
步骤 4:确认 Telegraf 设置
要验证 Telegraf 是否成功收集和写入数据,请使用以下方法之一查询您的 InfluxDB OSS 实例
InfluxDB CLI (influx)
$ influx
> SHOW TAG VALUES FROM cpu WITH KEY=host
curl
将 chronothan 和 supersecret 值替换为您实际的用户名和密码。
~# curl -G "https://:8086/query?db=telegraf&u=chronothan&p=supersecret&pretty=true" --data-urlencode "q=SHOW TAG VALUES FROM cpu WITH KEY=host"
预期输出类似于以下 JSON 代码块。 在这种情况下,telegraf 数据库对于 host 标签键 具有三个不同的 标签值:data-node-01、data-node-02 和 data-node-03。 这些值与集群中三个数据节点的主机名匹配;这意味着 Telegraf 正在成功地将来自这些主机的监控数据写入 InfluxDB OSS 实例!
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "cpu",
"columns": [
"key",
"value"
],
"values": [
[
"host",
"data-node-01"
],
[
"host",
"data-node-02"
],
[
"host",
"data-node-03"
]
]
}
]
}
]
}
Chronograf 设置
步骤 1:下载并安装 Chronograf
在与 InfluxDB 实例相同的服务器上下载并安装 Chronograf。 这不是必需的;您可以将 Chronograf 托管在单独的服务器上。
可以从 InfluxData 下载页面下载 Chronograf。
步骤 2:启动 Chronograf
~# sudo systemctl start chronograf
步骤 3:将 Chronograf 连接到 InfluxDB OSS 实例
要访问 Chronograf,请转到 https://:8888。 欢迎页面包含将 Chronograf 连接到该实例的说明。
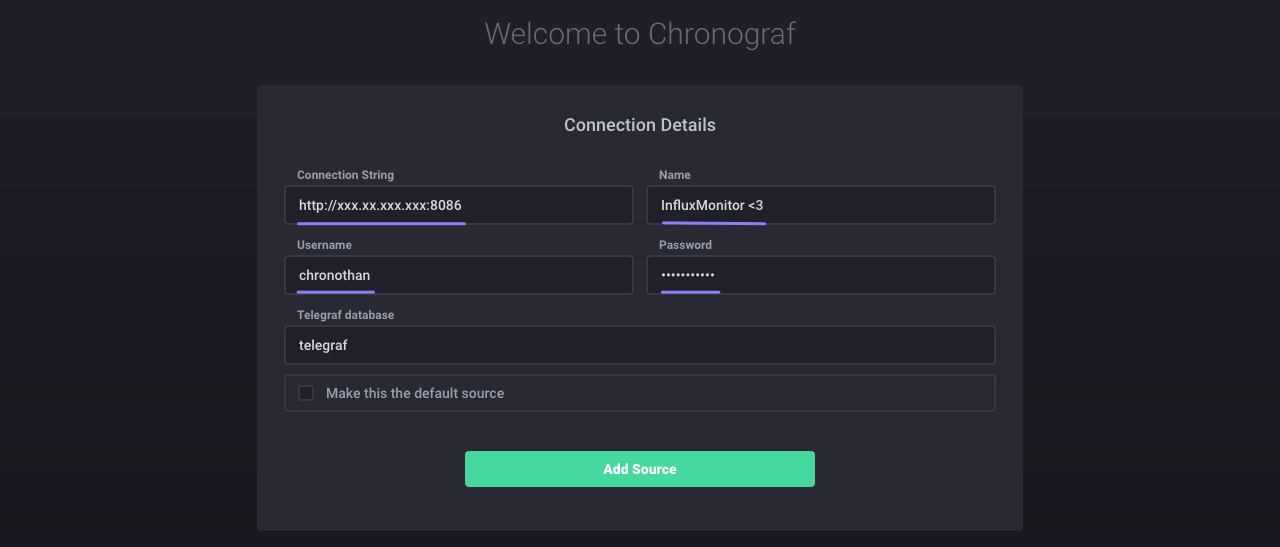
对于 连接字符串,输入您的 InfluxDB OSS 实例的主机名或 IP,并确保包含默认端口:8086。 接下来,命名您的数据源;这可以是您想要的任何名称。 最后,输入您的用户名和密码,然后单击 添加源。
步骤 4:在 Chronograf 中浏览监控数据
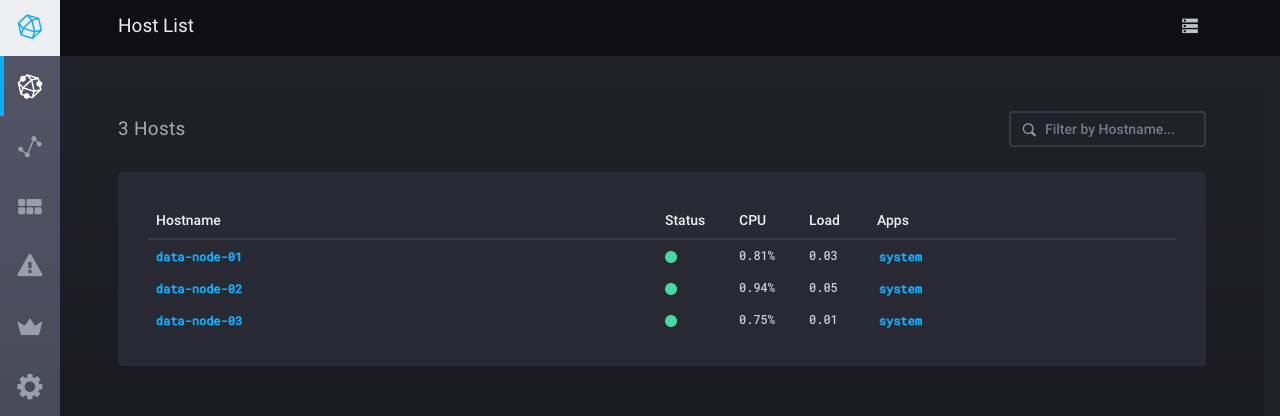
Chronograf 与您的 InfluxDB OSS 实例中的 Telegraf 数据配合使用。 主机列表页面显示您的数据节点的主机名、其状态、CPU 使用率、负载及其配置的应用程序。 在这种情况下,您仅启用了系统统计信息输入插件,因此 system 是 应用程序列中显示的单个应用程序。
单击 system 以查看该应用程序的 Chronograf 预置仪表板。 通过查看每个主机名的仪表板来密切关注您的数据节点
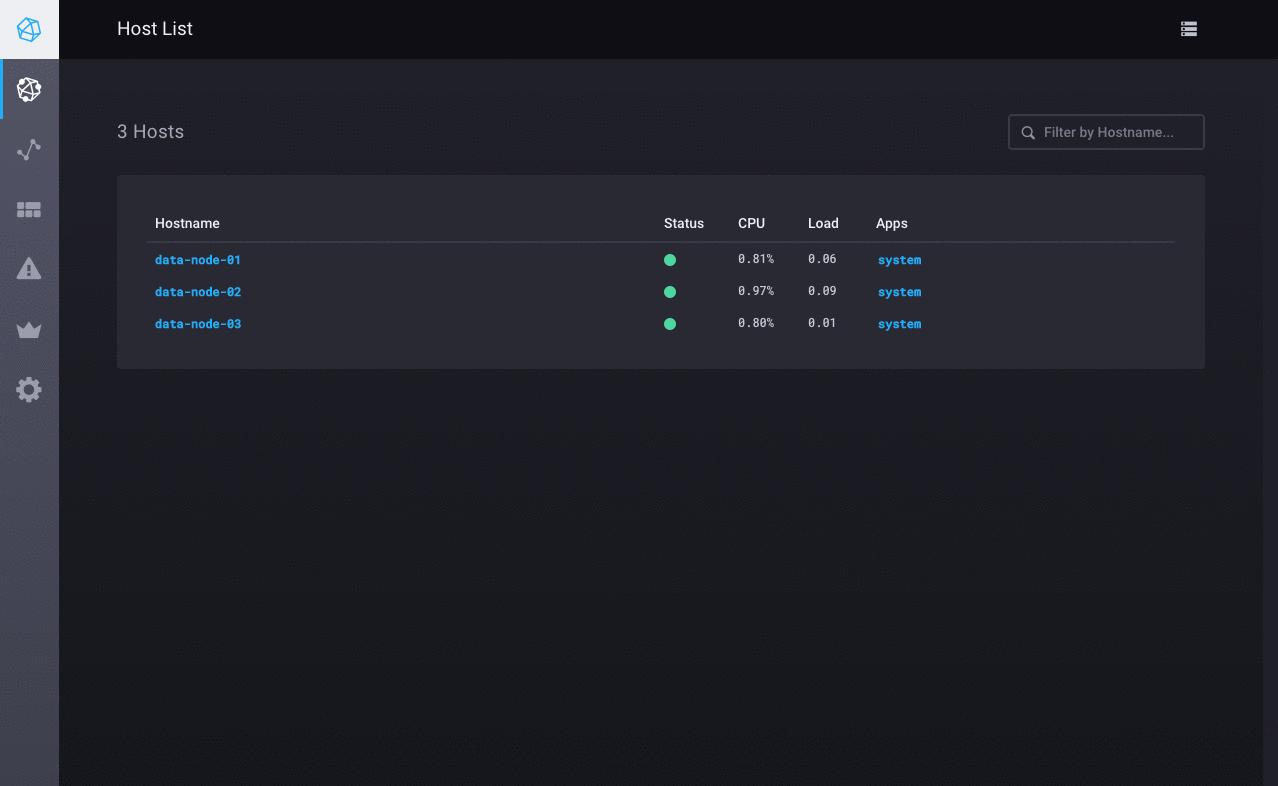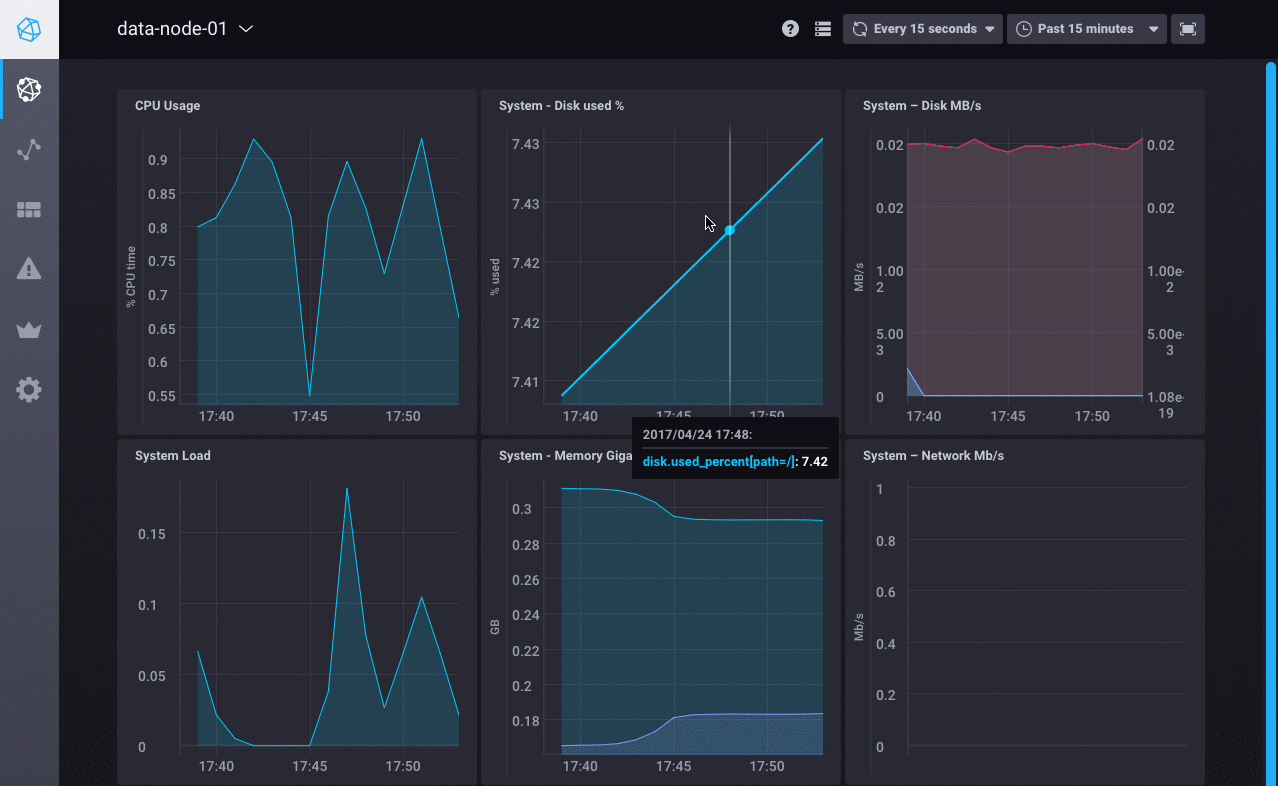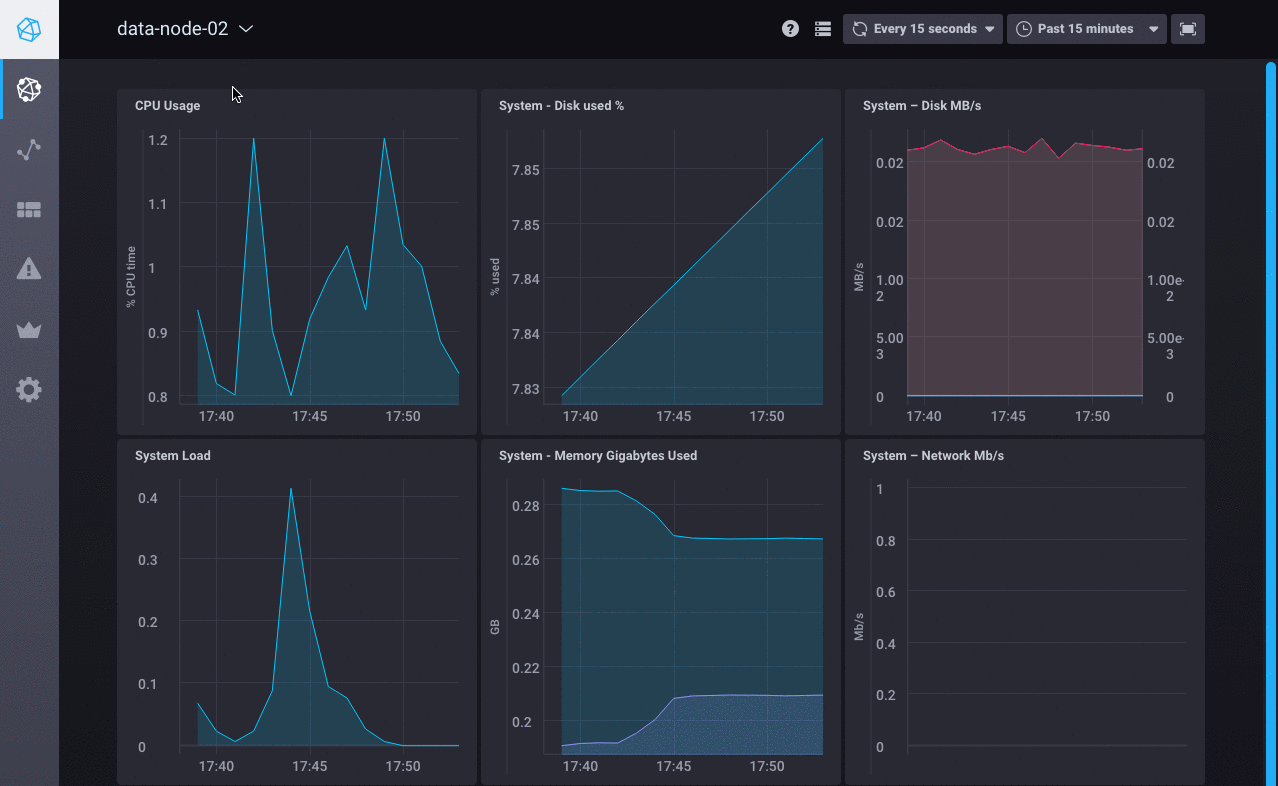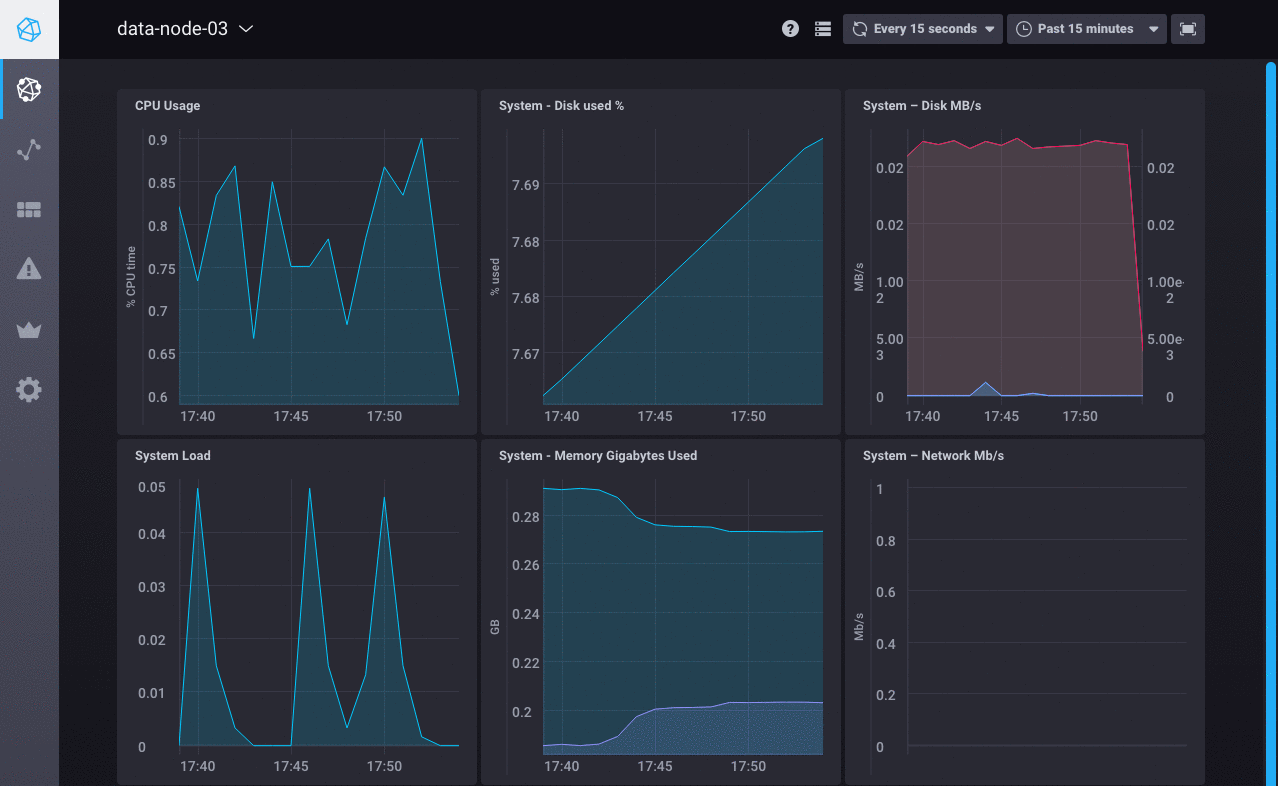
接下来,查看数据浏览器以使用监控数据创建自定义图表。 在下图中,Chronograf 查询编辑器用于可视化每个数据节点的空闲 CPU 使用率数据
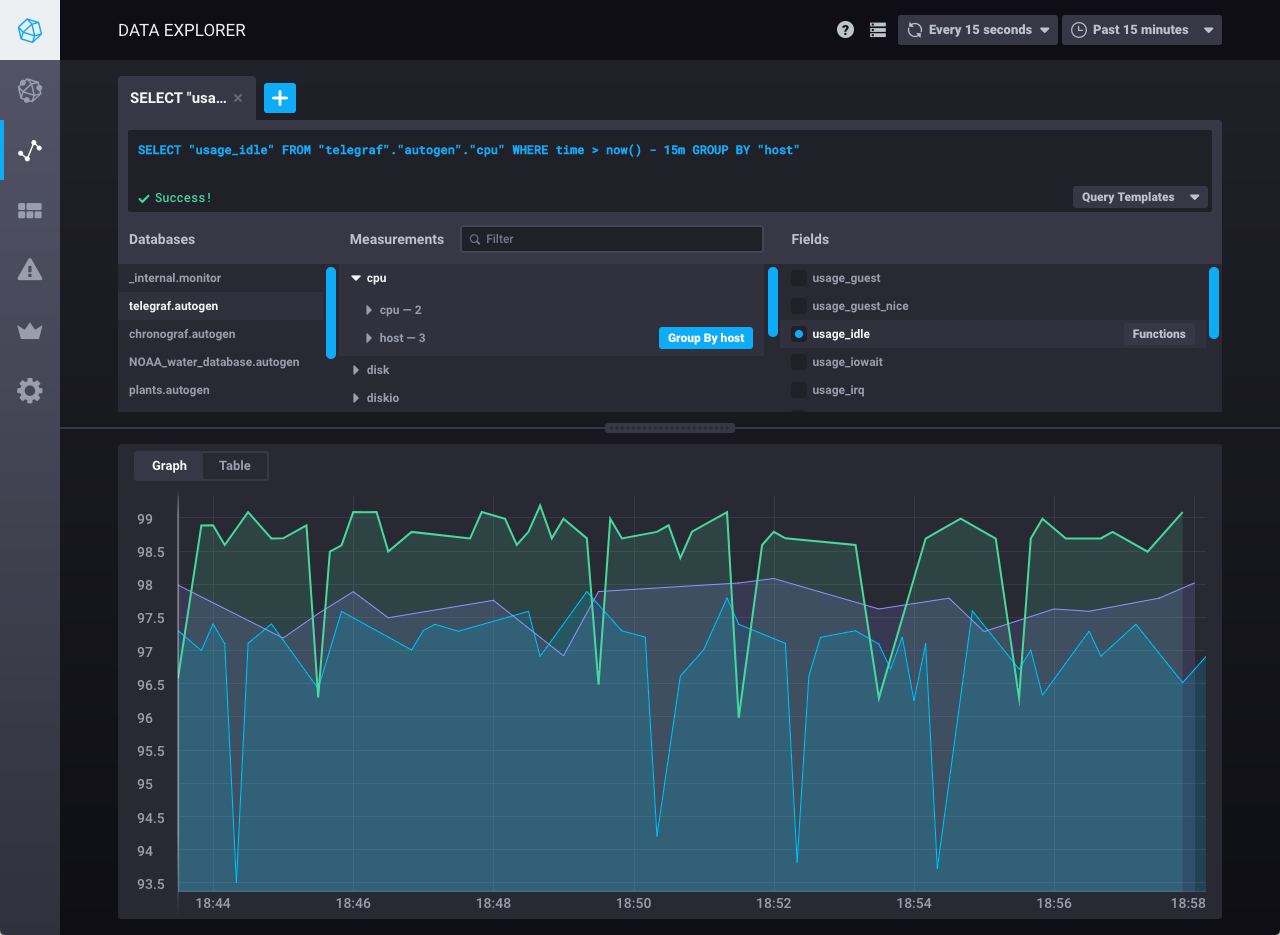
创建更多自定义图表,并将其保存到 Chronograf 中仪表板页面上的仪表板。 有关更多信息,请参阅创建 Chronograf 仪表板指南。
就这样! 您已成功配置 Telegraf 以收集和写入数据,配置 InfluxDB 以存储这些数据,并配置 Chronograf 以使用这些数据进行监控和可视化。
此页面是否对您有帮助?
感谢您的反馈!
支持和反馈
感谢您成为我们社区的一份子! 我们欢迎并鼓励您提供有关 Chronograf 和本文档的反馈和错误报告。 要查找支持,请使用以下资源