
排查磁盘使用率过高
您的 TICK 技术栈的组件耗尽磁盘空间是非常危险的。磁盘使用率达到 100% 的机器将无法正常工作。
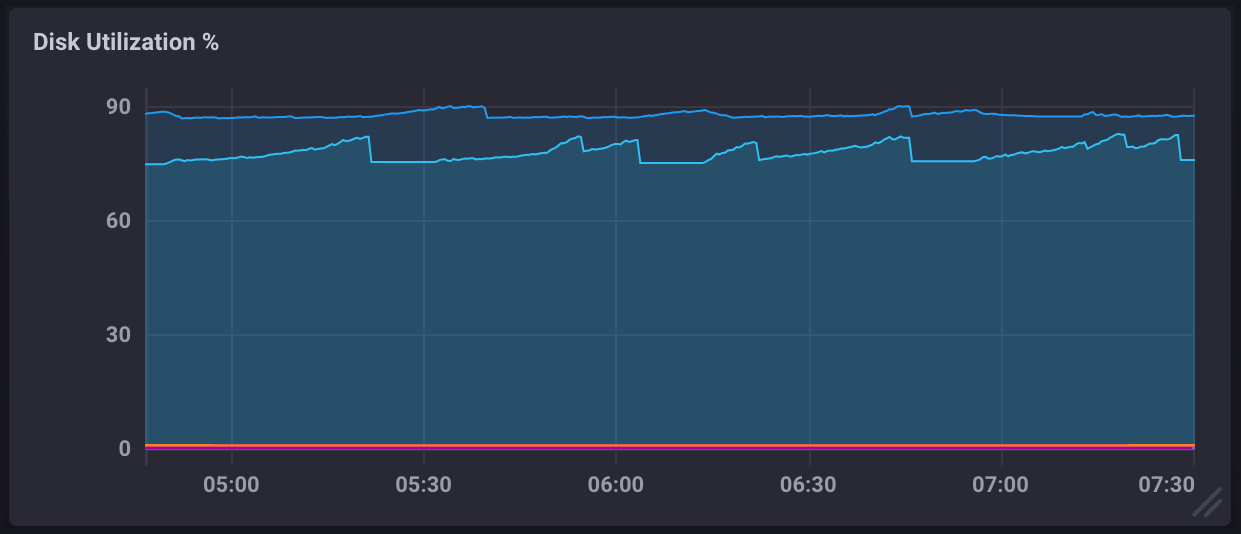
在监控仪表盘中,磁盘使用率过高会显示在磁盘利用率 % 指标中,并如下所示:
潜在原因
旧数据未被降采样
InfluxDB 使用保留策略和连续查询来降采样旧数据并节省磁盘空间。如果您使用无限保留策略或持续时间长的策略,高分辨率数据将占用越来越多的磁盘空间。
日志数据未被删除
日志数据在您的监控解决方案中非常有用,但它可能比其他类型的时间序列数据占用更多的磁盘空间。很多时候,日志数据存储在无限保留策略(默认保留策略持续时间)中,这意味着它永远不会被删除。这将不可避免地导致磁盘利用率过高。
解决方案
删除不必要的数据
解决磁盘利用率过高最简单的办法是删除旧的或不必要的数据。这可以通过强制方式(删除/丢弃数据)或通过调整保留策略的持续时间并调整连续查询中的降采样率来更优雅地完成。
日志数据保留策略
日志数据应该只存储在有限的保留策略中。您的保留策略的持续时间取决于您想保留日志数据多长时间。
是否使用连续查询在保留期结束时对日志数据进行降采样,由您决定,但旧的日志数据应该被降采样或完全删除。
扩展机器磁盘容量
如果删除或降采样数据不是一个选项,您可以随时扩展机器的磁盘容量。如何做到这一点取决于您的硬件或虚拟化配置,本文档未涵盖。
建议
设置磁盘使用警告
为了预防磁盘利用率问题,创建一个任务,在磁盘使用率超过特定阈值时通知您。下面的示例 TICKscript 设置了警告和严重磁盘使用阈值,并在这些阈值被跨越时向 Slack 发送消息。
有关 Kapacitor 任务和警告的信息,请参阅Kapacitor 警告文档。
磁盘使用率警告的示例 TICKscript
// Disk usage alerts
// Alert when disks are this % full
var warn_threshold = 80
var crit_threshold = 90
// Use a larger period here, as the telegraf data can be a little late
// if the server is under load.
var period = 10m
// How often to query for the period.
var every = 20m
var data = batch
|query('''
SELECT last(used_percent) FROM "telegraf"."default".disk
WHERE ("path" = '/influxdb/conf' or "path" = '/')
''')
.period(period)
.every(every)
.groupBy('host', 'path')
data
|alert()
.id('Alert: Disk Usage, Host: {{ index .Tags "host" }}, Path: {{ index .Tags "path" }}')
.warn(lambda: "last" > warn_threshold)
.message('{{ .ID }}, Used Percent: {{ index .Fields "last" | printf "%0.0f" }}%')
.details('')
.stateChangesOnly()
.slack()
data
|alert()
.id('Alert: Disk Usage, Host: {{ index .Tags "host" }}, Path: {{ index .Tags "path" }}')
.crit(lambda: "last" > crit_threshold)
.message('{{ .ID }}, Used Percent: {{ index .Fields "last" | printf "%0.0f" }}%')
.details('')
.slack()此页面是否有帮助?
感谢您的反馈!