
抓取和发现
Kapacitor 的发现和抓取功能可以从动态的远程目标列表中拉取数据。将这些功能与 TICKscripts 结合使用,可以监控目标、处理数据并将数据写入 InfluxDB。目前,Kapacitor 只支持 Prometheus 风格的目标。
注意:抓取和发现目前处于技术预览阶段。在后续版本中,配置和行为可能会发生变化。
内容
概述
下图概述了使用 Kapacitor 进行数据发现和抓取的基础设施。
图 1 – 抓取和发现工作流程
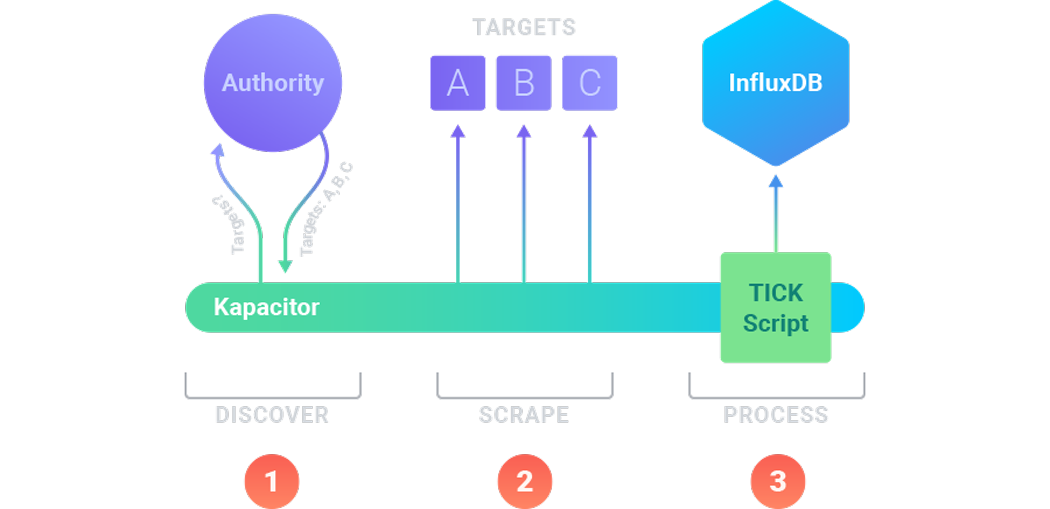
- 首先,Kapacitor 实现发现过程,以识别您基础设施中的可用目标。它会定期请求这些信息,并从 权威源 接收这些信息。在图中,权威源告知 Kapacitor 三个目标:
A、B和C。 - 接下来,Kapacitor 实现抓取过程,以从现有目标拉取指标数据。它会定期运行抓取过程。在这里,Kapacitor 请求目标
A、B和C的指标。运行在A、B和C上的应用程序在其 HTTP API 上公开了/metrics端点,该端点返回应用程序特定的统计信息。 - 最后,Kapacitor 根据配置的 TICKscripts 处理数据。使用 TICKscripts 对指标数据进行过滤、转换和其他任务。此外,如果需要存储数据,请配置一个 TICKscript 将其发送到 InfluxDB。
推送 vs. 拉取指标
通过结合发现和抓取,Kapacitor 使指标收集基础设施能够从目标拉取指标,而不是要求它们将指标推送到 InfluxDB。在目标生命周期较短的动态环境中,拉取指标具有多种优势。
配置抓取器和发现器
单个抓取器从单个发现器抓取目标。配置抓取器和发现器归结为单独配置它们,然后告知抓取器有关发现器的信息。
以下是抓取器的所有配置选项。
示例 1 – 抓取器配置
[[scraper]]
enabled = false
name = "myscraper"
# ID of the discoverer to use
discoverer-id = ""
# The kind of discoverer to use
discoverer-service = ""
db = "mydb"
rp = "myrp"
type = "prometheus"
scheme = "http"
metrics-path = "/metrics"
scrape-interval = "1m0s"
scrape-timeout = "10s"
username = ""
password = ""
bearer-token = ""
ssl-ca = ""
ssl-cert = ""
ssl-key = ""
ssl-server-name = ""
insecure-skip-verify = false可用的发现器
Kapacitor 支持以下服务进行发现
| 名称 | 描述 |
|---|---|
| azure | 发现托管在 Azure 中的目标。 |
| consul | 使用 Consul 服务发现来发现目标。 |
| dns | 通过 DNS 查询发现目标。 |
| ec2 | 发现托管在 AWS EC2 中的目标。 |
| file-discovery | 发现文件中列出的目标。 |
| gce | 发现托管在 GCE 中的目标。 |
| kubernetes | 发现托管在 Kubernetes 中的目标。 |
| marathon | 使用 Marathon 服务发现来发现目标。 |
| nerve | 使用 Nerve 服务发现来发现目标。 |
| serverset | 使用 Serversets 服务发现来发现目标。 |
| static-discovery | 静态列出目标。 |
| triton | 使用 Triton 服务发现来发现目标。 |
请参阅示例 配置文件,了解配置每个发现器的详细信息。
此页面是否有帮助?
感谢您的反馈!
支持和反馈
感谢您成为我们社区的一员!我们欢迎并鼓励您对 Kapacitor 和本文档提供反馈和错误报告。要获取支持,请使用以下资源: