
使用 Grafana 可视化数据
使用 Grafana 或 Grafana Cloud 查询和可视化 InfluxDB 3 Core 中的数据。
[Grafana] 使您能够查询、可视化、告警和探索存储在任何地方的指标、日志和跟踪。 [Grafana] 为您提供工具,将您的时间序列数据库 (TSDB) 数据转化为有见地的图表和可视化。
安装 Grafana 或登录 Grafana Cloud
注册 Grafana Cloud 或按照 Grafana 安装说明 为您的操作系统安装 Grafana。
如果本地运行 Grafana,请启用
newInfluxDSConfigPageDesign功能标志以使用最新的 InfluxDB 数据源插件。有关更多信息,请参阅 Grafana 文档中的 配置功能开关。
访问您的 Grafana Cloud 用户界面 (UI),或者,如果本地运行 Grafana,请 启动 Grafana 并在浏览器中访问 https://:3000。
将 Grafana Cloud 与本地 InfluxDB 实例一起使用
如果您需要将数据库保留在本地,请考虑本地运行 Grafana 而不是使用 Grafana Cloud,这样可以避免将数据库暴露给互联网。
要使用私有网络上运行的 InfluxDB 与 Grafana Cloud 结合使用,您必须为 Grafana Cloud 配置 私有数据源。
InfluxDB 数据源
InfluxDB 数据源插件包含在 Grafana 核心发行版中。使用该插件,您可以使用 SQL 和 InfluxQL 来查询和可视化 InfluxDB 3 Core 中的数据。
Grafana 12.2+
以下说明适用于启用了 newInfluxDSConfigPageDesign 功能标志的Grafana 12.2+。这引入了最新版本的 InfluxDB 核心插件。更新后的插件包括对 InfluxDB 3 基于产品的支持,例如 InfluxDB 3 Core 的SQL 支持,并且界面会根据您在 URL 和身份验证中的产品和查询语言选择进行动态调整。
开始之前
前提条件
- Grafana 12.2 或更高版本
- Grafana 中的管理员角色
- 具有数据库读取访问权限的您的 管理员令牌
快速参考:InfluxDB 3 Core 配置
| 配置 | Value |
|---|---|
| 产品选择 | InfluxDB Enterprise 3.x (当前没有 Core 菜单选项) |
| URL | 服务器 URL – 例如,https://:8181 |
| 查询语言 | SQL (需要 HTTP/2),InfluxQL |
| 身份验证 | 管理员令牌(如果启用了身份验证) |
| 数据库/存储桶 | 数据库名称 |
创建 InfluxDB 数据源
- 在您的 Grafana 界面中,点击左侧边栏的 **Connections**。
- 点击 **Data sources**。
- 点击 **Add new data source**。
- 搜索并选择 **InfluxDB**。此时会显示 InfluxDB 数据源配置页面。
- 在 **Settings** 选项卡中,为您的数据源输入一个 **Name**。
配置 URL 和身份验证
在 **URL and authentication** 部分,配置以下内容
- URL:您的 InfluxDB 3 Core 服务器 URL – 例如,
https://:8181 - Product:从下拉列表中,选择 InfluxDB Enterprise 3.x (当前没有 Core 菜单选项)InfluxDB Enterprise 3.x
- Query Language:选择 SQL 或 InfluxQL
- (可选) 根据您的环境需要,配置 **Advanced HTTP Settings**、**Auth** 和 **TLS/SSL Settings**。
配置数据库设置
此部分中的字段会根据您在 URL 和身份验证中的查询语言选择而变化。
SQL 配置
当您选择 SQL 作为查询语言时,请配置以下字段
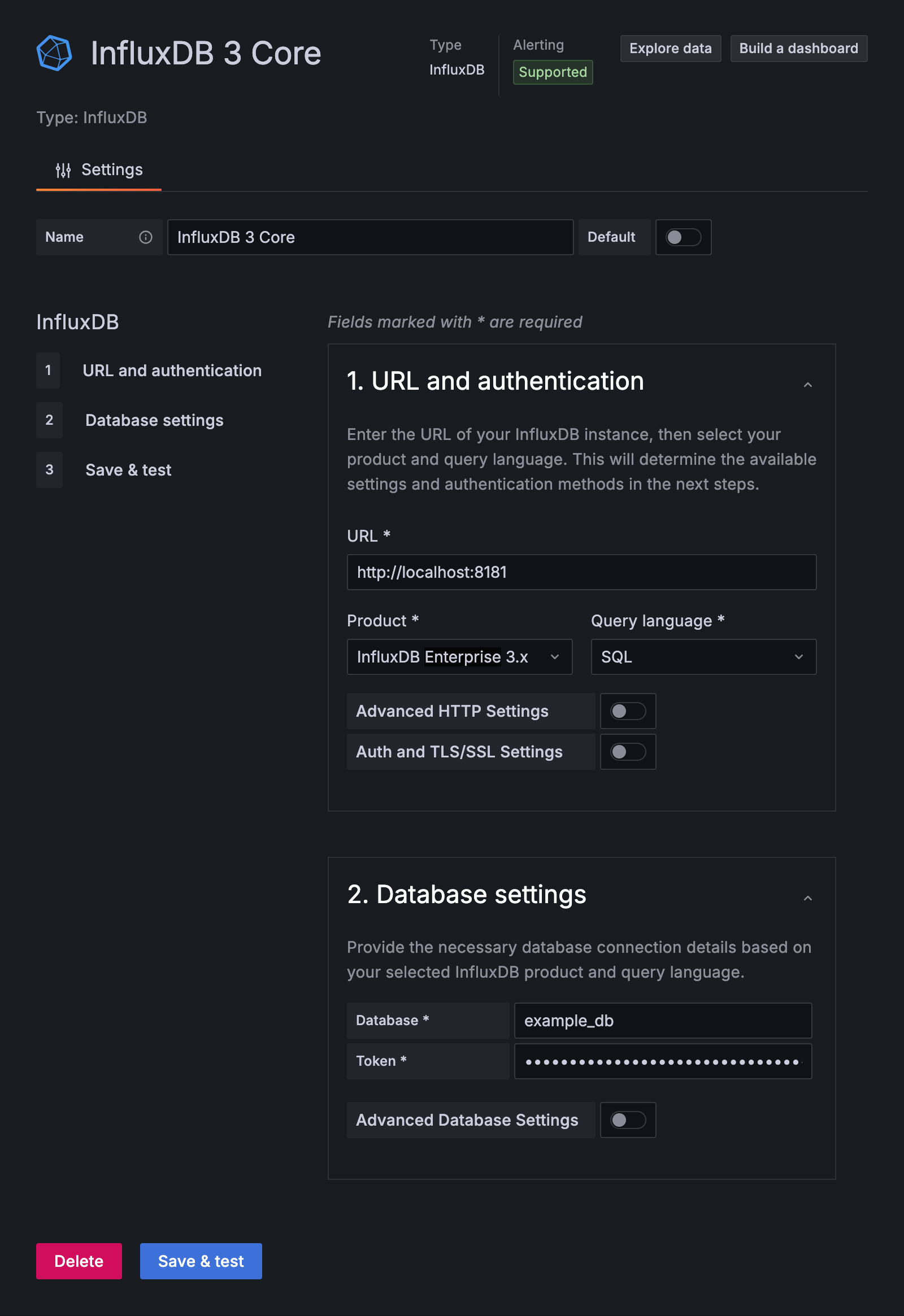
使用不带 TLS/SSL 的 SQL
如果使用 SQL 查询不带 TLS/SSL 的 InfluxDB 3 Core,请在 InfluxDB 数据源配置中启用 Insecure Connection 选项。
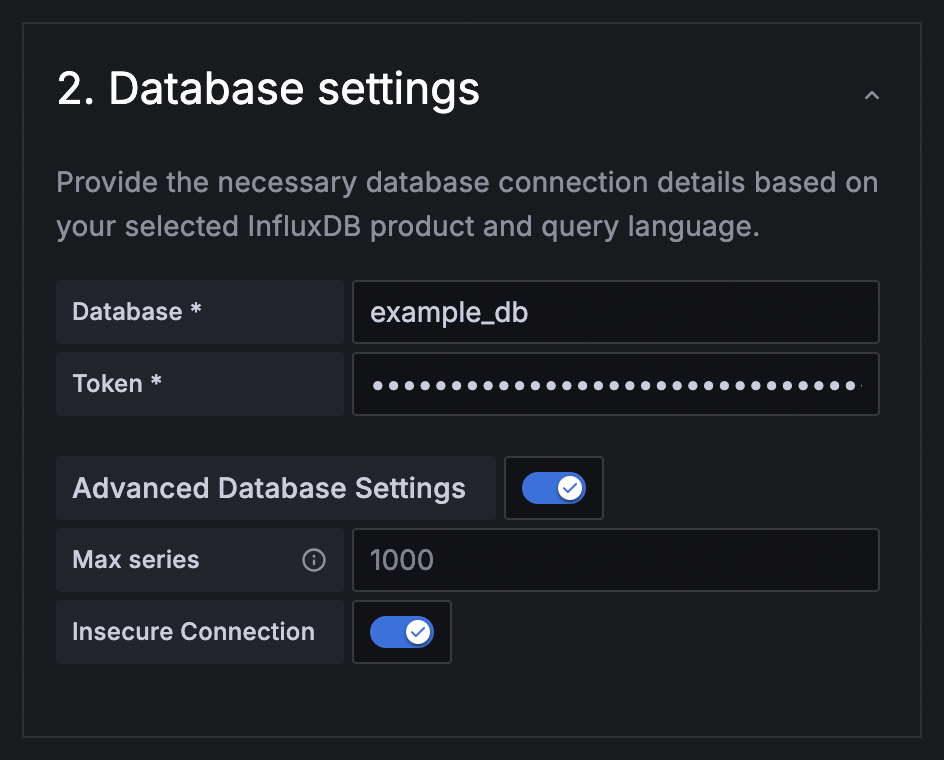
- 在 **Database settings** 下,启用 **Advanced Database Settings**。
- 启用 **Insecure Connection**。
Grafana 通过代理进行查询需要 HTTP/2
对于 SQL 查询,Grafana 使用 Flight SQL 协议 (gRPC) 来查询 InfluxDB 3 Core,这需要 HTTP/2。如果您通过代理(如 HAProxy、nginx 或负载均衡器)查询 InfluxDB 3 Core,请验证您的代理已配置为支持 HTTP/2。如果没有 HTTP/2 支持,通过 Grafana 进行的 SQL 查询将无法连接。
InfluxQL 查询使用 HTTP/1.1 并且不受此要求的影响。
点击 **Save & test**。Grafana 尝试连接到 InfluxDB 3 Core 并返回测试结果。
InfluxQL 配置
当您选择 InfluxQL 作为查询语言时,请配置以下字段
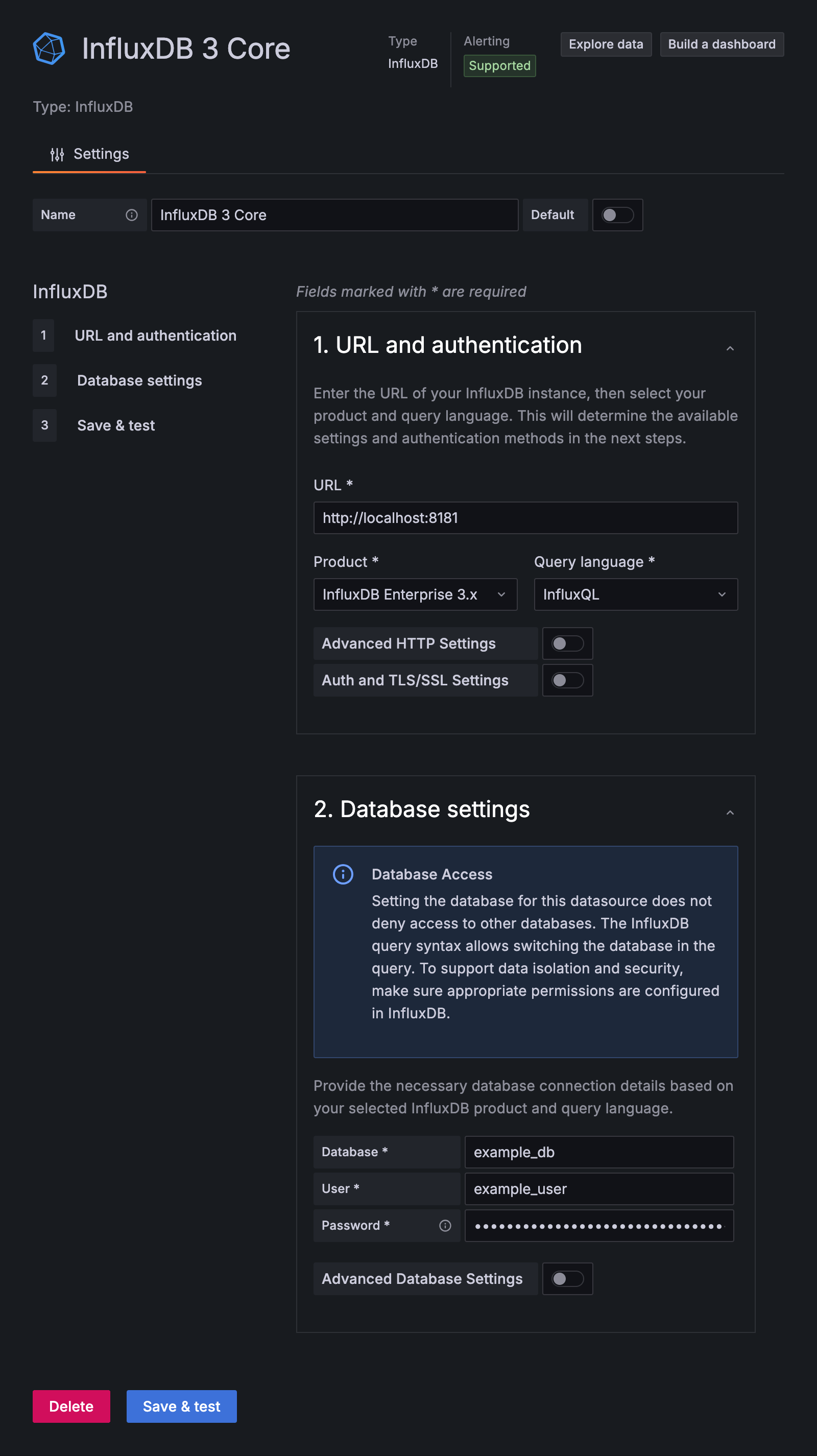
点击 **Save & test**。Grafana 尝试连接到 InfluxDB 3 Core 并返回测试结果。
查询和可视化数据
配置好 InfluxDB 连接后,使用 Grafana 来查询和可视化时间序列数据。
使用 Grafana 查询 InfluxDB
在 配置并保存 InfluxDB 数据源后,使用 Grafana 来构建、运行和检查针对 InfluxDB 3 Core 的查询。
在使用 InfluxDB 3 Core SQL 实现时,一个 bucket 等同于一个 database,一个 measurement 等同于一个 table,而 time、fields 和 tags 则被结构化为 columns。要了解更多信息,请参阅 查询数据。
点击 **Explore**。
在下拉菜单中,选择要查询的已保存的 InfluxDB 数据源。
使用 SQL 查询表单构建您的查询
Table:选择要查询的表(measurement)。
Column:选择一个或多个要作为查询结果列返回的字段和标签。
使用 SQL,选择
time列以包含时间戳与数据一起。Grafana 依赖time列来正确绘制时间序列数据的图表。可选:切换 **filter** 以生成 WHERE 子句语句。
- WHERE:配置要包含在
WHERE子句中的条件表达式。
- WHERE:配置要包含在
可选:切换 **group** 以生成 GROUP BY 子句语句。
- GROUP BY:选择要分组的列。如果您在 SELECT 列表中包含聚合函数,则必须按一个或多个查询的列进行分组。SQL 将为每个组返回聚合值。
推荐:切换 **order** 以生成 ORDER BY 子句语句。
- ORDER BY:选择要排序的列。您可以按时间、多个字段或标签进行排序。要按降序排序,请选择 DESC。
推荐:将格式更改为 **Time series**。
- 使用 **Format** 下拉菜单更改查询结果的格式。例如,要将查询结果可视化为时间序列,请选择 Time series。
点击 **Run query** 来执行查询。
- 点击 **Explore**。
- 在下拉菜单中,选择您要查询的 **InfluxDB** 数据源。
- 使用 InfluxQL 查询表单构建您的查询
- FROM:选择要查询的 measurement。
- WHERE:要过滤查询结果,请输入一个条件表达式。
- SELECT:选择要查询的字段以及要应用的聚合函数。聚合函数应用于
GROUP BY子句中定义的每个时间间隔。 - GROUP BY:默认情况下,Grafana 按时间分组数据以进行下采样并提高查询性能。您还可以添加其他标签进行分组。
- 点击 **Run query** 来执行查询。
配置好 InfluxDB 连接后,使用 Grafana 来查询和可视化时间序列数据。
使用 Grafana 构建可视化
有关使用 Grafana 创建可视化的全面教程,请参阅 Grafana 文档。
Grafana 中的查询检查
要了解有关 Grafana 中查询管理和检查的更多信息,请参阅 Grafana Explore 文档。
此页面是否有帮助?
感谢您的反馈!
支持和反馈
感谢您成为我们社区的一员!我们欢迎并鼓励您对 InfluxDB 3 Core 和本文档提供反馈和错误报告。要获得支持,请使用以下资源
具有年度合同或支持合同的客户可以 联系 InfluxData 支持。