
将数据从 InfluxDB Cloud 迁移到 InfluxDB OSS
要将数据从 InfluxDB Cloud 迁移到 InfluxDB OSS,请从 InfluxDB Cloud 查询数据,并将数据写入 InfluxDB OSS。由于完整的数据迁移可能会超出您组织的限制和可调整的配额,请分批迁移数据。
以下指南提供有关设置 InfluxDB OSS 任务的说明,该任务以基于时间的批次从 InfluxDB Cloud 存储桶查询数据,并将每个批次写入 InfluxDB OSS 存储桶。
针对 InfluxDB Cloud 中数据的所有查询都受您组织的速率限制和可调整配额的约束。
设置迁移
在 InfluxDB Cloud 中,创建一个 API 令牌,并授予读取访问权限给您要迁移的存储桶。
在 InfluxDB OSS 中:
迁移完成后,每个后续迁移任务执行都将失败,并显示以下错误
error exhausting result iterator: error calling function "die" @41:9-41:86:
Batch range is beyond the migration range. Migration is complete.
迁移任务
配置迁移
使用
task.every选项指定您希望任务运行的频率。请参阅确定您的任务间隔。在
migration记录中定义以下属性migration
- start:要包含在迁移中的最早时间。请参阅确定您的迁移开始时间。
- stop:要包含在迁移中的最晚时间。
- batchInterval:每个基于时间的批次的持续时间。请参阅确定您的批次间隔。
- batchBucket:InfluxDB OSS 存储桶,用于存储迁移批次元数据。
- sourceHost:要从中迁移数据的 InfluxDB Cloud 区域 URL。
- sourceOrg:要从中迁移数据的 InfluxDB Cloud 组织。
- sourceToken:InfluxDB Cloud API 令牌。为了保证 API 令牌的安全,请将其作为密钥存储在 InfluxDB OSS 中。
- sourceBucket:要从中迁移数据的 InfluxDB Cloud 存储桶。
- destinationBucket:要迁移数据到的 InfluxDB OSS 存储桶。
迁移 Flux 脚本
import "array"
import "experimental"
import "influxdata/influxdb/secrets"
// Configure the task
option task = {every: 5m, name: "Migrate data from InfluxDB Cloud"}
// Configure the migration
migration = {
start: 2022-01-01T00:00:00Z,
stop: 2022-02-01T00:00:00Z,
batchInterval: 1h,
batchBucket: "migration",
sourceHost: "https://cloud2.influxdata.com",
sourceOrg: "example-cloud-org",
sourceToken: secrets.get(key: "INFLUXDB_CLOUD_TOKEN"),
sourceBucket: "example-cloud-bucket",
destinationBucket: "example-oss-bucket",
}
// batchRange dynamically returns a record with start and stop properties for
// the current batch. It queries migration metadata stored in the
// `migration.batchBucket` to determine the stop time of the previous batch.
// It uses the previous stop time as the new start time for the current batch
// and adds the `migration.batchInterval` to determine the current batch stop time.
batchRange = () => {
_lastBatchStop =
(from(bucket: migration.batchBucket)
|> range(start: migration.start)
|> filter(fn: (r) => r._field == "batch_stop")
|> filter(fn: (r) => r.srcOrg == migration.sourceOrg)
|> filter(fn: (r) => r.srcBucket == migration.sourceBucket)
|> last()
|> findRecord(fn: (key) => true, idx: 0))._value
_batchStart =
if exists _lastBatchStop then
time(v: _lastBatchStop)
else
migration.start
return {start: _batchStart, stop: experimental.addDuration(d: migration.batchInterval, to: _batchStart)}
}
// Define a static record with batch start and stop time properties
batch = {start: batchRange().start, stop: batchRange().stop}
// Check to see if the current batch start time is beyond the migration.stop
// time and exit with an error if it is.
finished =
if batch.start >= migration.stop then
die(msg: "Batch range is beyond the migration range. Migration is complete.")
else
"Migration in progress"
// Query all data from the specified source bucket within the batch-defined time
// range. To limit migrated data by measurement, tag, or field, add a `filter()`
// function after `range()` with the appropriate predicate fn.
data = () =>
from(host: migration.sourceHost, org: migration.sourceOrg, token: migration.sourceToken, bucket: migration.sourceBucket)
|> range(start: batch.start, stop: batch.stop)
// rowCount is a stream of tables that contains the number of rows returned in
// the batch and is used to generate batch metadata.
rowCount =
data()
|> count()
|> group(columns: ["_start", "_stop"])
|> sum()
// emptyRange is a stream of tables that acts as filler data if the batch is
// empty. This is used to generate batch metadata for empty batches and is
// necessary to correctly increment the time range for the next batch.
emptyRange = array.from(rows: [{_start: batch.start, _stop: batch.stop, _value: 0}])
// metadata returns a stream of tables representing batch metadata.
metadata = () => {
_input =
if exists (rowCount |> findRecord(fn: (key) => true, idx: 0))._value then
rowCount
else
emptyRange
return
_input
|> map(
fn: (r) =>
({
_time: now(),
_measurement: "batches",
srcOrg: migration.sourceOrg,
srcBucket: migration.sourceBucket,
dstBucket: migration.destinationBucket,
batch_start: string(v: batch.start),
batch_stop: string(v: batch.stop),
rows: r._value,
percent_complete:
float(v: int(v: r._stop) - int(v: migration.start)) / float(
v: int(v: migration.stop) - int(v: migration.start),
) * 100.0,
}),
)
|> group(columns: ["_measurement", "srcOrg", "srcBucket", "dstBucket"])
}
// Write the queried data to the specified InfluxDB OSS bucket.
data()
|> to(bucket: migration.destinationBucket)
// Generate and store batch metadata in the migration.batchBucket.
metadata()
|> experimental.to(bucket: migration.batchBucket)
配置帮助
监控迁移进度
InfluxDB Cloud 迁移社区模板安装了本指南中概述的迁移任务,以及用于监控正在运行的数据迁移的仪表板。
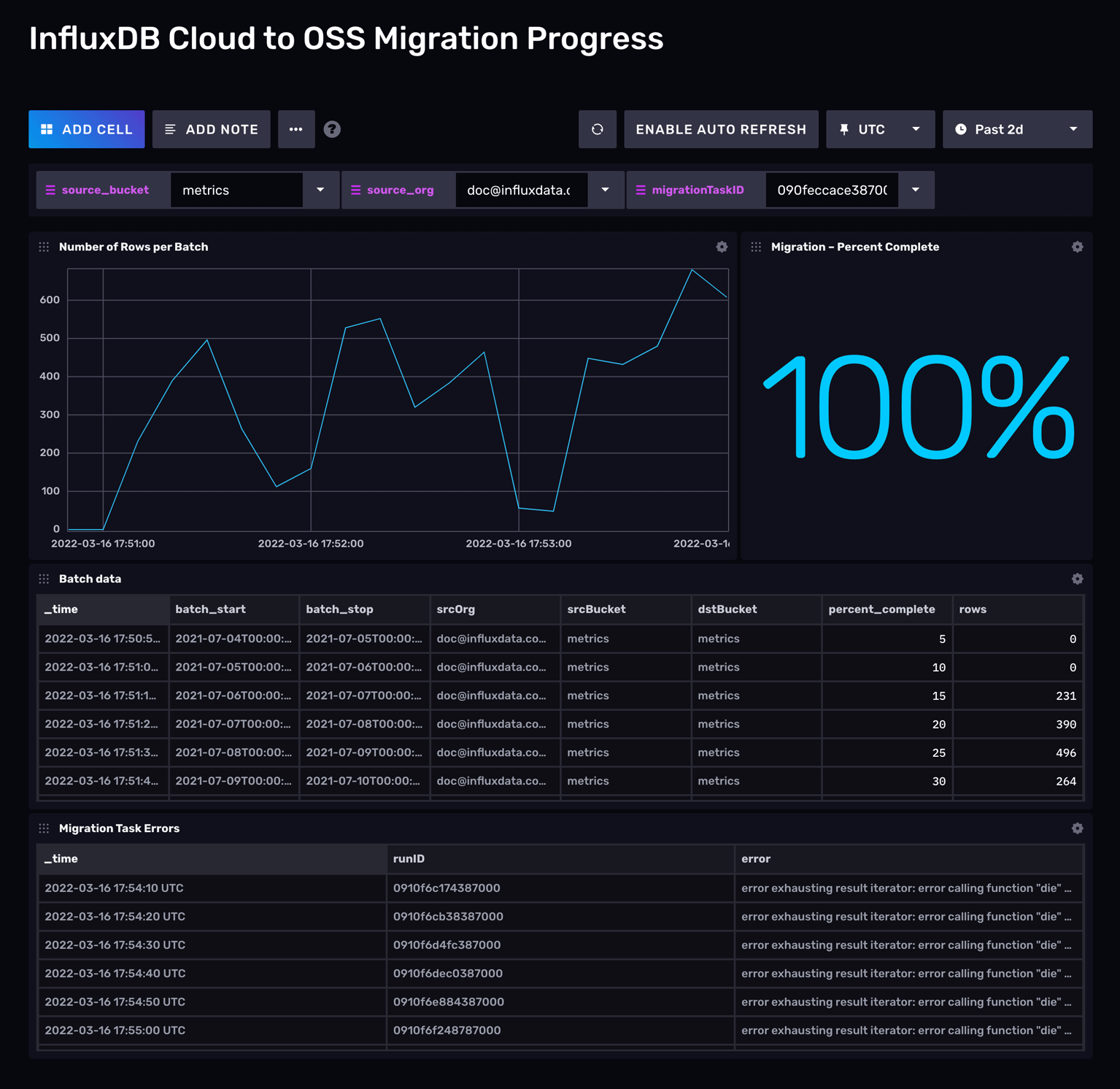
排查迁移任务失败问题
如果迁移任务失败,请查看您的任务日志以识别具体错误。以下是迁移任务失败的常见原因。
超出速率限制
如果您的数据迁移导致您超出 InfluxDB Cloud 组织的限制和配额,则任务将返回类似于以下的错误
too many requests
可能的解决方案:
- 更新迁移任务中的
migration.batchInterval设置以使用较小的间隔。然后,每个批次将查询较少的数据。
API 令牌无效
如果您添加为 INFLUXDB_CLOUD_SECRET 的 API 令牌没有对您的 InfluxDB Cloud 存储桶的读取访问权限,则任务将返回类似于以下的错误
unauthorized access
可能的解决方案:
- 确保 API 令牌具有对您的 InfluxDB Cloud 存储桶的读取访问权限。
- 生成一个新的 InfluxDB Cloud API 令牌,并授予其对您要迁移的存储桶的读取访问权限。然后,使用新令牌更新您的 InfluxDB OSS 实例中的
INFLUXDB_CLOUD_TOKEN密钥。
查询超时
InfluxDB Cloud 查询超时时间为 90 秒。如果从批次间隔返回数据的时间超过此时间,则查询将超时,并且任务将失败。
可能的解决方案:
- 更新迁移任务中的
migration.batchInterval设置以使用较小的间隔。然后,每个批次将查询较少的数据,并花费更少的时间返回结果。
批次大小过大
如果您的批次大小过大,则任务将返回类似于以下的错误
internal error: error calling function "metadata" @97:1-97:11: error calling function "findRecord" @67:32-67:69: wrong number of fields
可能的解决方案:
- 更新迁移任务中的
migration.batchInterval设置以使用较小的间隔,并减少每个批次检索的数据量。
此页是否对您有帮助?
感谢您的反馈!
支持和反馈
感谢您成为我们社区的一份子!我们欢迎并鼓励您提供关于 InfluxDB 和本文档的反馈和错误报告。要寻求支持,请使用以下资源
拥有年度合同或支持合同的客户可以联系 InfluxData 支持。