
热图可视化
热图在 x 轴和 y 轴上显示数据分布,其中颜色表示不同浓度的数据点。
从左上角的可视化下拉菜单中选择 热图 选项。
热图行为
热图将数据点划分为“箱”——可视化的分段,具有 X 轴和 Y 轴的上限和下限。 箱大小选项 确定每个箱的边界。落入箱内的总点数决定了它的值和颜色。较暖或较亮的颜色表示较高的箱值或箱内点的密度。
热图控件
要查看 热图 控件,请单击可视化下拉菜单旁边的 自定义。
数据
- X 轴列:选择要在 x 轴上显示的列。
- Y 轴列:选择要在 y 轴上显示的列。
- 时间格式:选择时间格式。选项包括
- YYYY-MM-DD HH:mm:ss ZZ
- YYYY-MM-DD hh:mm:ss a ZZ
- DD/MM/YYYY HH:mm:ss.sss
- DD/MM/YYYY hh:mm:ss.sss a
- MM/DD/YYYY HH:mm:ss.sss
- MM/DD/YYYY hh:mm:ss.sss a
- YYYY/MM/DD HH:mm:ss
- YYYY/MM/DD hh:mm:ss a
- HH:mm
- hh:mm a
- HH:mm:ss
- hh:mm:ss a
- HH:mm:ss ZZ
- hh:mm:ss a ZZ
- HH:mm:ss.sss
- hh:mm:ss.sss a
- MMMM D, YYYY HH:mm:ss
- MMMM D, YYYY hh:mm:ss a
- dddd, MMMM D, YYYY HH:mm:ss
- dddd, MMMM D, YYYY hh:mm:ss a
选项
- 颜色方案:选择用于热图的颜色方案。
- 箱大小:指定每个箱的大小。默认为 10。
X 轴
- X 轴标签:x 轴的标签。
- 生成 X 轴刻度线:选择生成 x 轴刻度线的方法
- 自动:选择自动生成刻度线。
- 自定义:要自定义 x 轴刻度线的数量,请选择此选项,然后输入以下内容
- 刻度线总数:输入要显示的刻度线总数。
- 刻度线起始于:输入刻度线开始的值。
- 刻度线间隔:输入每个刻度线之间的间隔。
- X 轴域:x 轴值范围。
- 自动:根据数据集中的值自动确定值范围。
- 自定义:手动指定最小 y 轴值、最大 y 轴值或通过同时包含两者来指定范围。
- 最小值:最小 x 轴值。
- 最大值:最大 x 轴值。
Y 轴
- Y 轴标签:y 轴的标签。
- Y 轴刻度前缀:要添加到 y 值的后缀。
- Y 轴刻度后缀:要添加到 y 值的后缀。
- 生成 Y 轴刻度线:选择生成 y 轴刻度线的方法
- 自动:选择自动生成刻度线。
- 自定义:要自定义 y 轴刻度线的数量,请选择此选项,然后输入以下内容
- 刻度线总数:输入要显示的刻度线总数。
- 刻度线起始于:输入刻度线开始的值。
- 刻度线间隔:输入每个刻度线之间的间隔。
- Y 轴域:y 轴值范围。
- 自动:根据数据集中的值自动确定值范围。
- 自定义:手动指定最小 y 轴值、最大 y 轴值或通过同时包含两者来指定范围。
- 最小值:最小 y 轴值。
- 最大值:最大 y 轴值。
悬停图例
- 方向:选择悬停时出现的图例的方向
- 水平:选择水平显示图例。
- 垂直:选择垂直显示图例。
- 不透明度:使用滑块调整图例不透明度。
- 行为行着色:选择以彩色显示图例行。
热图示例
跨指标关联
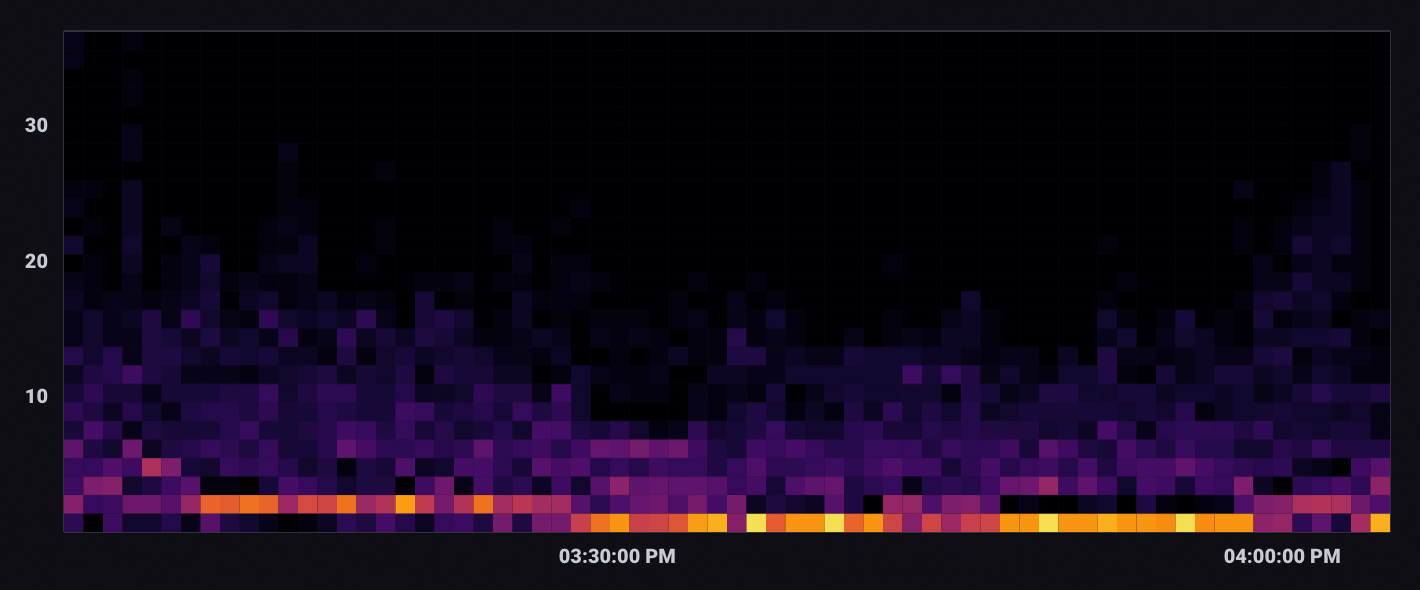
以下示例探讨了 CPU 和内存使用率之间可能存在的关联。它使用 Telegraf Mem 和 CPU 输入插件收集的数据。
连接 CPU 和内存使用率
以下查询在 _time 上连接 CPU 和内存使用率。输出表中的每一行都包含 _value_cpu 和 _value_mem 列。
cpu = from(bucket: "example-bucket")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "cpu" and r._field == "usage_system" and r.cpu == "cpu-total")
mem = from(bucket: "example-bucket")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
join(tables: {cpu: cpu, mem: mem}, on: ["_time"], method: "inner")
使用热图可视化关联
在热图可视化控件中,_value_cpu 被选为 X 轴列,_value_mem 被选为 Y 轴列。每个轴的域也已自定义,以考虑列值之间的比例差异。
重要说明
热图和散点图之间的差异
热图和 散点图 都可视化 X 轴和 Y 轴上数据点的分布。但是,在某些情况下,热图可以更好地显示点密度。
例如,以下仪表盘单元格可视化相同的查询结果
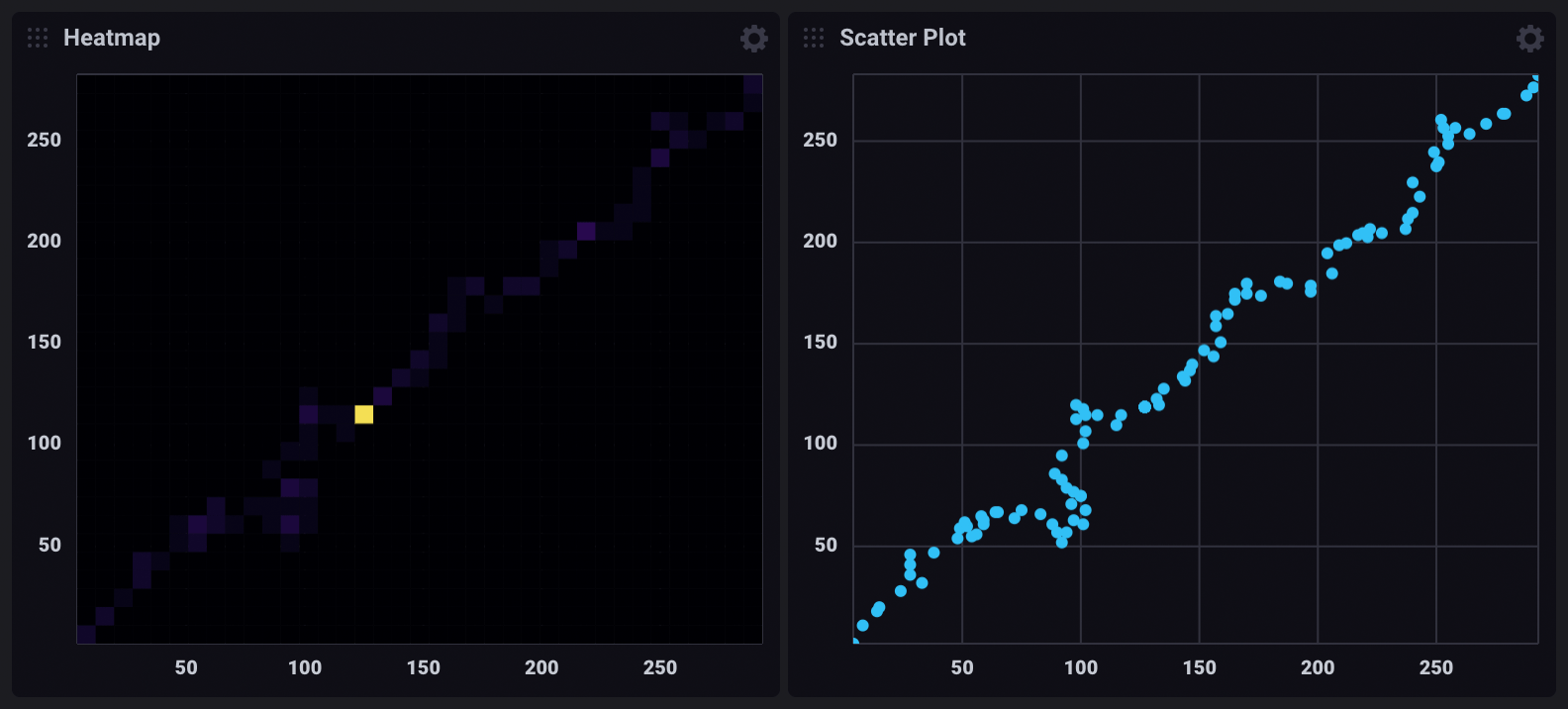
热图指示孤立的高点密度,这在散点图中不可见。在散点图可视化中,共享相同 X 和 Y 坐标的点显示为单个点。
此页内容是否对您有帮助?
感谢您的反馈!
支持和反馈
感谢您成为我们社区的一份子!我们欢迎并鼓励您提供关于 InfluxDB 和此文档的反馈和错误报告。要查找支持,请使用以下资源
拥有年度或支持合同的客户 可以 联系 InfluxData 支持。