
InfluxQL 分析函数
使用技术分析函数将算法应用于您的数据——通常用于分析金融和投资数据。
以下每个分析函数都涵盖了语法,包括传递给函数的参数,以及如何使用该函数的示例。示例使用NOAA 水样数据。
预测分析
预测分析函数是一种技术分析算法,用于预测和预报未来值。
HOLT_WINTERS()
使用 Holt-Winters 季节性方法返回 N 个预测的 字段值。支持 int64 和 float64 字段值 数据类型。适用于以一致时间间隔发生的数据。需要 InfluxQL 函数和 GROUP BY time() 子句,以确保 Holt-Winters 函数对规则数据进行操作。
使用 HOLT_WINTERS() 来
- 预测数据值何时将超过给定的阈值
- 将预测值与实际值进行比较,以检测数据中的异常
语法
SELECT HOLT_WINTERS[_WITH-FIT](<function>(<field_key>),<N>,<S>) FROM_clause [WHERE_clause] GROUP_BY_clause [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]
HOLT_WINTERS(function(field_key),N,S) 返回指定 字段键 的 N 个季节性调整的预测字段值。
N 个预测值以与 GROUP BY time() 间隔相同的间隔出现。如果您的 GROUP BY time() 间隔为 6m 且 N 为 3,您将收到三个预测值,每个值间隔六分钟。
S 是季节性模式参数,并根据 GROUP BY time() 间隔分隔季节性模式的长度。如果您的 GROUP BY time() 间隔为 2m 且 S 为 3,则季节性模式每六分钟发生一次,即每三个数据点。如果您不想对预测值进行季节性调整,请将 S 设置为 0 或 1.
HOLT_WINTERS_WITH_FIT(function(field_key),N,S) 除了指定字段键的 N 个季节性调整的预测字段值外,还返回拟合值。
示例
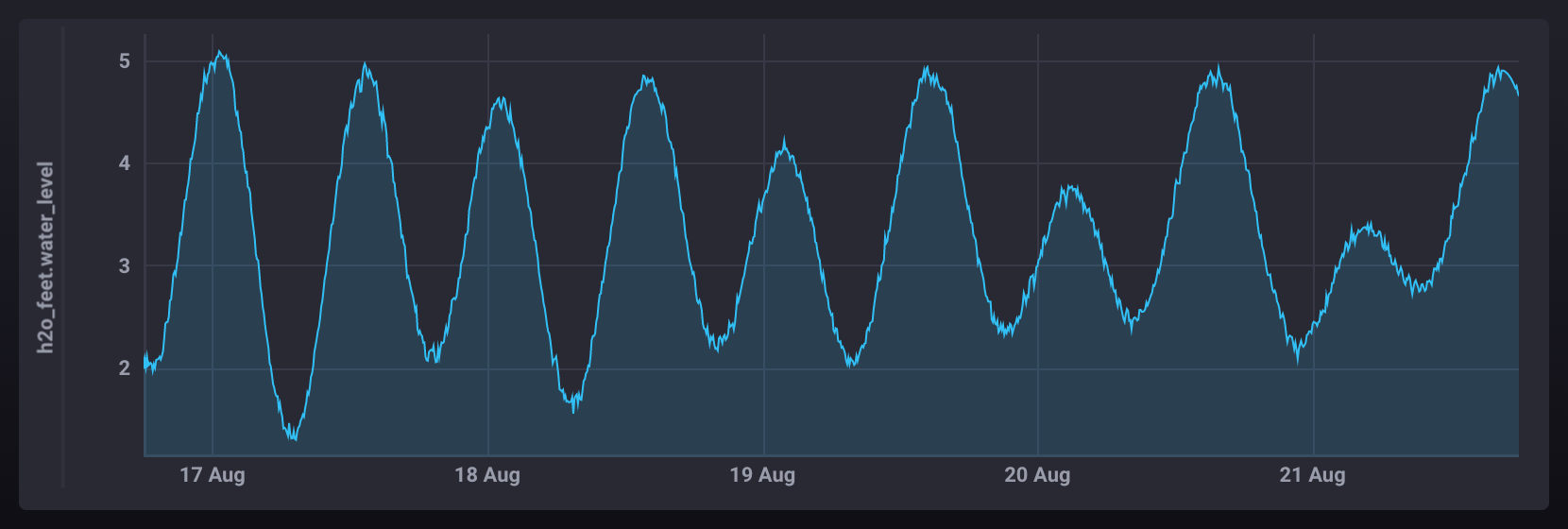
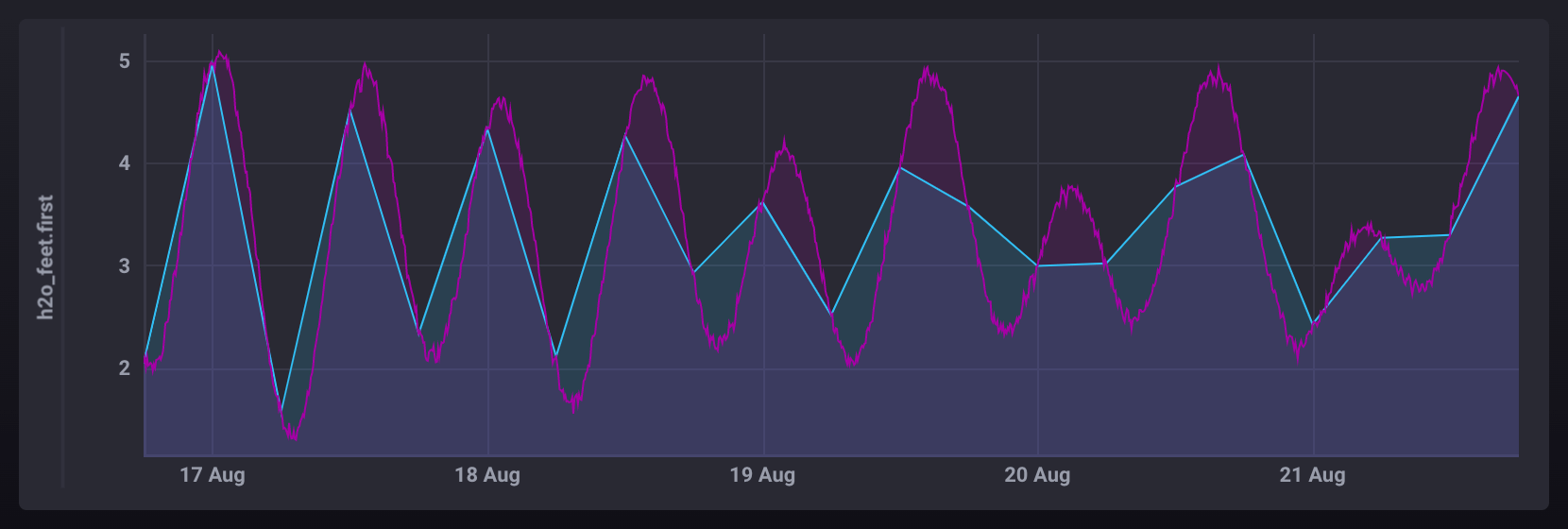
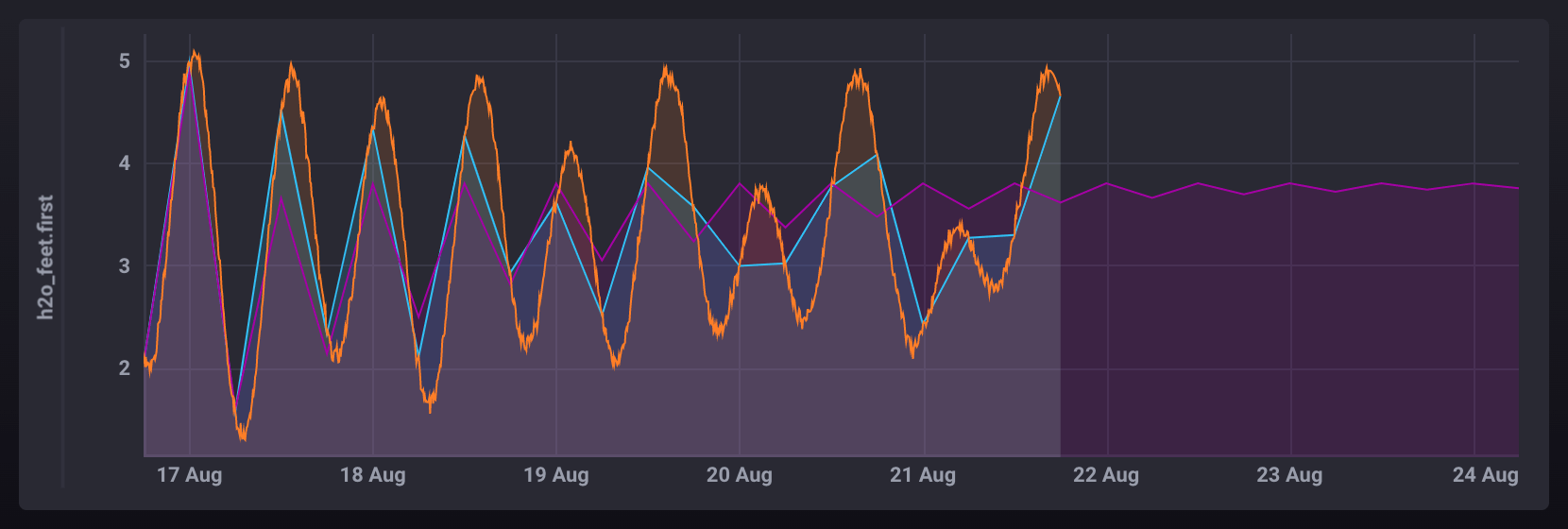
HOLT_WINTERS() 的常见问题
接收的点少于 N 个
在某些情况下,您可能会收到少于 N 参数请求的预测点。当数学变得不稳定且无法预测更多点时,通常会发生这种情况。在这种情况下,HOLT_WINTERS() 可能不适合数据集,或者季节性调整参数无效。
技术分析函数
技术分析函数将广泛使用的算法应用于您的数据。虽然它们主要用于金融和投资领域,但它们在其他行业也有应用。
对于技术分析函数,请考虑是否包含 PERIOD、HOLD_PERIOD 和 WARMUP_TYPE 参数
PERIOD
必需,整数,最小值=1
算法的样本大小,即对算法输出有显着影响的历史样本数。例如,2 表示当前点及其之前的点。该算法使用指数衰减率来确定历史点的权重,通常称为 alpha (α)。PERIOD 控制衰减率。
注意:较旧的点仍然可能产生影响。
HOLD_PERIOD
整数,最小值=-1
算法在发出结果之前需要的样本数。默认值 -1 表示该值基于算法、PERIOD 和 WARMUP_TYPE。验证此值是否足以使算法发出有意义的结果。
默认保持周期
对于大多数技术分析函数,默认的 HOLD_PERIOD 由函数和 WARMUP_TYPE 确定,如下表所示
| 算法 \ 预热类型 | 简单 | 指数 | 无 |
|---|---|---|---|
| EXPONENTIAL_MOVING_AVERAGE | PERIOD - 1 | PERIOD - 1 | 不适用 |
| DOUBLE_EXPONENTIAL_MOVING_AVERAGE | ( PERIOD - 1 ) * 2 | PERIOD - 1 | 不适用 |
| TRIPLE_EXPONENTIAL_MOVING_AVERAGE | ( PERIOD - 1 ) * 3 | PERIOD - 1 | 不适用 |
| TRIPLE_EXPONENTIAL_DERIVATIVE | ( PERIOD - 1 ) * 3 + 1 | PERIOD | 不适用 |
| RELATIVE_STRENGTH_INDEX | PERIOD | PERIOD | 不适用 |
| CHANDE_MOMENTUM_OSCILLATOR | PERIOD | PERIOD | PERIOD - 1 |
Kaufman 算法默认保持周期
| 算法 | 默认保持周期 |
|---|---|
| KAUFMANS_EFFICIENCY_RATIO() | PERIOD |
| KAUFMANS_ADAPTIVE_MOVING_AVERAGE() | PERIOD |
WARMUP_TYPE
default=‘exponential’
控制算法如何为前 PERIOD 个样本初始化。它本质上是算法具有不完整样本集的持续时间。
简单
前 PERIOD 个样本的简单移动平均 (SMA)。这是 ta-lib 使用的方法。
指数
具有缩放 alpha (α) 的指数移动平均 (EMA)。对于第一个点使用 PERIOD=1 的 EMA,对于第二个点使用 PERIOD=2,依此类推,直到算法消耗了 PERIOD 个点。由于算法立即开始使用 EMA,因此当使用此方法且 HOLD_PERIOD 未指定或 -1 时,算法可能在比 simple 小得多的样本大小后开始发出点。
无
算法根本不执行任何平滑处理。ta-lib 使用的方法。当使用此方法且 HOLD_PERIOD 未指定时,HOLD_PERIOD 默认为 PERIOD - 1。
注意: none 预热类型仅适用于 CHANDE_MOMENTUM_OSCILLATOR() 函数。
CHANDE_MOMENTUM_OSCILLATOR()
Chande Momentum Oscillator (CMO) 是 Tushar Chande 开发的一种技术动量指标。CMO 指标是通过计算所有近期较高数据点之和与所有近期较低数据点之和之间的差值,然后将结果除以给定时间段内所有数据移动的总和来创建的。结果乘以 100,得到 -100 到 +100 的范围。来源
支持 按标签分组 的 GROUP BY 子句,但不按时间分组 的 GROUP BY 子句。要将 CHANDE_MOMENTUM_OSCILLATOR() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
CHANDE_MOMENTUM_OSCILLATOR([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period>, [warmup_type]])
参数
- period
- (可选) hold_period
- (可选) warmup_type
CHANDE_MOMENTUM_OSCILLATOR(field_key, 2)
返回与 字段键 关联的字段值,这些字段值使用 Chande Momentum Oscillator 算法处理,周期为 2 值,默认保持周期和预热类型。
CHANDE_MOMENTUM_OSCILLATOR(field_key, 10, 9, 'none')
返回与 字段键 关联的字段值,这些字段值使用 Chande Momentum Oscillator 算法处理,周期为 10 值,保持周期为 9 值,预热类型为 none。
CHANDE_MOMENTUM_OSCILLATOR(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用 Chande Momentum Oscillator 算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 CHANDE_MOMENTUM_OSCILLATOR() 函数时包含一个聚合函数。
CHANDE_MOMENTUM_OSCILLATOR(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的 Chande Momentum Oscillator 算法以及默认的保持周期和预热类型进行处理。
CHANDE_MOMENTUM_OSCILLATOR(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的 Chande Momentum Oscillator 算法以及默认的保持周期和预热类型进行处理。
CHANDE_MOMENTUM_OSCILLATOR() 支持 int64 和 float64 字段值数据类型。
EXPONENTIAL_MOVING_AVERAGE()
指数移动平均线 (EMA)(或指数加权移动平均线)是一种类似于简单移动平均线的移动平均线类型,但它赋予最新数据更高的权重。
与简单移动平均线相比,这种类型的移动平均线对近期数据变化的反应更快。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。要将 EXPONENTIAL_MOVING_AVERAGE() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
EXPONENTIAL_MOVING_AVERAGE([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period)[, <warmup_type]])
EXPONENTIAL_MOVING_AVERAGE(field_key, 2)
返回使用指数移动平均算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
EXPONENTIAL_MOVING_AVERAGE(field_key, 10, 9, 'exponential')
返回使用指数移动平均算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 9,预热类型为 exponential。
EXPONENTIAL_MOVING_AVERAGE(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用指数移动平均算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 EXPONENTIAL_MOVING_AVERAGE() 函数时包含一个聚合函数。
EXPONENTIAL_MOVING_AVERAGE(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的指数移动平均算法以及默认的保持周期和预热类型进行处理。
EXPONENTIAL_MOVING_AVERAGE(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的指数移动平均算法以及默认的保持周期和预热类型进行处理。
EXPONENTIAL_MOVING_AVERAGE() 支持 int64 和 float64 字段值数据类型。
参数
- period
- (可选) hold_period
- (可选) warmup_type
DOUBLE_EXPONENTIAL_MOVING_AVERAGE()
双指数移动平均线 (DEMA) 试图通过对近期值赋予更高的权重来消除与移动平均线相关的固有滞后。名称暗示这是通过应用双指数平滑来实现的,但事实并非如此。 EMA 的值被加倍。为了使值与实际数据保持一致并消除滞后,从先前加倍的 EMA 中减去“EMA 的 EMA”值。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。要将 DOUBLE_EXPONENTIAL_MOVING_AVERAGE() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
DOUBLE_EXPONENTIAL_MOVING_AVERAGE([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period)[, <warmup_type]])
DOUBLE_EXPONENTIAL_MOVING_AVERAGE(field_key, 2)
返回使用双指数移动平均算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
DOUBLE_EXPONENTIAL_MOVING_AVERAGE(field_key, 10, 9, 'exponential')
返回使用双指数移动平均算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 9,预热类型为 exponential。
DOUBLE_EXPONENTIAL_MOVING_AVERAGE(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用双指数移动平均算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 DOUBLE_EXPONENTIAL_MOVING_AVERAGE() 函数时包含一个聚合函数。
DOUBLE_EXPONENTIAL_MOVING_AVERAGE(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的双指数移动平均算法以及默认的保持周期和预热类型进行处理。
DOUBLE_EXPONENTIAL_MOVING_AVERAGE(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的双指数移动平均算法以及默认的保持周期和预热类型进行处理。
DOUBLE_EXPONENTIAL_MOVING_AVERAGE() 支持 int64 和 float64 字段值数据类型。
参数
- period
- (可选) hold_period
- (可选) warmup_type
KAUFMANS_EFFICIENCY_RATIO()
考夫曼效率比率,或简称“效率比率” (ER),是通过将一段时间内的数据变化除以为实现该变化而发生的数据移动的绝对总和来计算得出的。所得比率介于 0 和 1 之间,值越高表示市场效率或趋势性越高。
ER 与Chande Momentum Oscillator (CMO) 非常相似。不同之处在于,CMO 考虑了市场方向,但如果您取绝对 CMO 并除以 100,您将得到效率比率。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。要将 KAUFMANS_EFFICIENCY_RATIO() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
KAUFMANS_EFFICIENCY_RATIO([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period>])
KAUFMANS_EFFICIENCY_RATIO(field_key, 2)
返回使用效率指数算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
KAUFMANS_EFFICIENCY_RATIO(field_key, 10, 10)
返回使用效率指数算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 10。
KAUFMANS_EFFICIENCY_RATIO(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用效率指数算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 KAUFMANS_EFFICIENCY_RATIO() 函数时包含一个聚合函数。
KAUFMANS_EFFICIENCY_RATIO(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的效率指数算法以及默认的保持周期和预热类型进行处理。
KAUFMANS_EFFICIENCY_RATIO(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的效率指数算法以及默认的保持周期和预热类型进行处理。
KAUFMANS_EFFICIENCY_RATIO() 支持 int64 和 float64 字段值数据类型。
参数
- period
- (可选) hold_period
KAUFMANS_ADAPTIVE_MOVING_AVERAGE()
考夫曼自适应移动平均线 (KAMA) 是一种旨在考虑样本噪声或波动率的移动平均线。当数据波动相对较小且噪声较低时,KAMA 将紧密跟踪数据点。当数据波动扩大时,KAMA 将进行调整并从更远的距离跟踪数据。这种趋势跟踪指标可用于识别总体趋势、时间转折点和过滤数据移动。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。要将 KAUFMANS_ADAPTIVE_MOVING_AVERAGE() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
KAUFMANS_ADAPTIVE_MOVING_AVERAGE([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period>])
KAUFMANS_ADAPTIVE_MOVING_AVERAGE(field_key, 2)
返回使用考夫曼自适应移动平均算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
KAUFMANS_ADAPTIVE_MOVING_AVERAGE(field_key, 10, 10)
返回使用考夫曼自适应移动平均算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 10。
KAUFMANS_ADAPTIVE_MOVING_AVERAGE(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用考夫曼自适应移动平均算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 KAUFMANS_ADAPTIVE_MOVING_AVERAGE() 函数时包含一个聚合函数。
KAUFMANS_ADAPTIVE_MOVING_AVERAGE(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的考夫曼自适应移动平均算法以及默认的保持周期和预热类型进行处理。
KAUFMANS_ADAPTIVE_MOVING_AVERAGE(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的考夫曼自适应移动平均算法以及默认的保持周期和预热类型进行处理。
KAUFMANS_ADAPTIVE_MOVING_AVERAGE() 支持 int64 和 float64 字段值数据类型。
参数
- period
- (可选) hold_period
TRIPLE_EXPONENTIAL_MOVING_AVERAGE()
三重指数移动平均线 (TEMA) 滤除了传统移动平均线的波动性。虽然名称暗示它是一种三重指数平滑,但它实际上是单指数移动平均线、双指数移动平均线和三重指数移动平均线的组合。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。要将 TRIPLE_EXPONENTIAL_MOVING_AVERAGE() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
TRIPLE_EXPONENTIAL_MOVING_AVERAGE([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period)[, <warmup_type]])
TRIPLE_EXPONENTIAL_MOVING_AVERAGE(field_key, 2)
返回使用三重指数移动平均算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
TRIPLE_EXPONENTIAL_MOVING_AVERAGE(field_key, 10, 9, 'exponential')
返回使用三重指数移动平均算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 9,预热类型为 exponential。
TRIPLE_EXPONENTIAL_MOVING_AVERAGE(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用三重指数移动平均算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 TRIPLE_EXPONENTIAL_MOVING_AVERAGE() 函数时包含一个聚合函数。
TRIPLE_EXPONENTIAL_MOVING_AVERAGE(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的三重指数移动平均算法以及默认的保持周期和预热类型进行处理。
TRIPLE_EXPONENTIAL_MOVING_AVERAGE(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的三重指数移动平均算法以及默认的保持周期和预热类型进行处理。
TRIPLE_EXPONENTIAL_MOVING_AVERAGE() 支持 int64 和 float64 字段值数据类型。
参数
- period
- (可选) hold_period
- (可选) warmup_type
TRIPLE_EXPONENTIAL_DERIVATIVE()
三重指数导数指标,通常称为“TRIX”,是一种用于识别超卖和超买市场的振荡器,也可用作动量指标。 TRIX 计算三重指数移动平均线,该平均线是数据输入在一段时间内的对数。从先前值中减去先前值。这可以防止周期短于定义周期的周期被指标考虑在内。
与许多振荡器一样,TRIX 在零线附近振荡。当用作振荡器时,正值表示超买市场,而负值表示超卖市场。当用作动量指标时,正值表示动量正在增加,而负值表示动量正在减少。许多分析师认为,当 TRIX 向上穿过零线时,会发出买入信号,而当它向下穿过零线时,会发出卖出信号。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。要将 TRIPLE_EXPONENTIAL_DERIVATIVE() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
TRIPLE_EXPONENTIAL_DERIVATIVE([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period)[, <warmup_type]])
TRIPLE_EXPONENTIAL_DERIVATIVE(field_key, 2)
返回使用三重指数导数算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
TRIPLE_EXPONENTIAL_DERIVATIVE(field_key, 10, 10, 'exponential')
返回使用三重指数导数算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 10,预热类型为 exponential。
TRIPLE_EXPONENTIAL_DERIVATIVE(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用三重指数导数算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 TRIPLE_EXPONENTIAL_DERIVATIVE() 函数时包含一个聚合函数。
TRIPLE_EXPONENTIAL_DERIVATIVE(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的三重指数导数算法以及默认的保持周期和预热类型进行处理。
TRIPLE_EXPONENTIAL_DERIVATIVE(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的三重指数导数算法以及默认的保持周期和预热类型进行处理。
TRIPLE_EXPONENTIAL_DERIVATIVE() 支持 int64 和 float64 字段值数据类型。
RELATIVE_STRENGTH_INDEX()
相对强度指数 (RSI) 是一种动量指标,它比较指定时间段内近期增加和减少的幅度,以衡量数据移动的速度和变化。来源
支持 按标签分组的 GROUP BY 子句,但不支持 按时间间隔分组的 GROUP BY 子句。
要将 RELATIVE_STRENGTH_INDEX() 与 GROUP BY time() 子句一起使用,请参阅高级语法。
基本语法
RELATIVE_STRENGTH_INDEX([ * | <field_key> | /regular_expression/ ], <period>[, <hold_period)[, <warmup_type]])
RELATIVE_STRENGTH_INDEX(field_key, 2)
返回使用相对强度指数算法处理的字段键关联的字段值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
RELATIVE_STRENGTH_INDEX(field_key, 10, 10, 'exponential')
返回使用相对强度指数算法处理的字段键关联的字段值,该算法的周期值为 10,保持周期值为 10,预热类型为 exponential。
RELATIVE_STRENGTH_INDEX(MEAN(<field_key>), 2) ... GROUP BY time(1d)
返回使用相对强度指数算法处理的字段键关联的字段值的平均值,该算法的周期值为 2,并使用默认的保持周期和预热类型。
注意: 当使用 GROUP BY 子句聚合数据时,您必须在调用 RELATIVE_STRENGTH_INDEX() 函数时包含一个聚合函数。
RELATIVE_STRENGTH_INDEX(/regular_expression/, 2)
返回与每个匹配正则表达式的字段键关联的字段值,这些字段值使用周期值为 2 的相对强度指数算法以及默认的保持周期和预热类型进行处理。
RELATIVE_STRENGTH_INDEX(*, 2)
返回与measurement中每个字段键关联的字段值,这些字段值使用周期值为 2 的相对强度指数算法以及默认的保持周期和预热类型进行处理。
RELATIVE_STRENGTH_INDEX() 支持 int64 和 float64 字段值数据类型。
参数
- period
- (可选) hold_period
- (可选) warmup_type
此页是否对您有帮助?
感谢您的反馈!