
使用 Flux 进行窗口和聚合数据
时间序列数据的一个常见操作是将数据分组到时间窗口中,或者“窗口化”数据,然后对窗口化值进行聚合,得到新的值。本指南将指导您如何使用 Flux 进行窗口化和聚合数据,并演示数据在此过程中的形状。
如果您刚开始学习 Flux 查询,可以查看以下内容
以下示例深入介绍了进行窗口化和聚合数据所需的步骤。虽然 aggregateWindow() 函数 会为您执行这些操作,但了解数据在此过程中的形状有助于成功创建所需输出。
数据集
在本指南中,定义一个变量表示您的基数据集。以下示例查询主机机的内存使用情况。
dataSet = from(bucket: "example-bucket")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "mem" and r._field == "used_percent")
|> drop(columns: ["host"])
此示例删除了返回数据中的 host 列,因为内存数据仅跟踪单个主机,这简化了输出表。删除 host 列是可选的,不推荐在监控多个主机上的内存时使用。
dataSet 现在可以用来表示您的基数据,其外观类似于以下示例
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:00.000000000Z 71.11611366271973
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:10.000000000Z 67.39630699157715
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:20.000000000Z 64.16666507720947
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:30.000000000Z 64.19951915740967
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:40.000000000Z 64.2122745513916
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:50:50.000000000Z 64.22209739685059
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 64.6336555480957
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:10.000000000Z 64.16516304016113
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:20.000000000Z 64.18349742889404
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:30.000000000Z 64.20474052429199
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:40.000000000Z 68.65062713623047
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:50.000000000Z 67.20139980316162
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 70.9143877029419
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:10.000000000Z 64.14549350738525
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:20.000000000Z 64.15379047393799
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:30.000000000Z 64.1592264175415
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:40.000000000Z 64.18190002441406
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:50.000000000Z 64.28837776184082
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 64.29731845855713
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:10.000000000Z 64.36963081359863
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:20.000000000Z 64.37397003173828
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:30.000000000Z 64.44413661956787
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:40.000000000Z 64.42906856536865
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:50.000000000Z 64.44573402404785
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.48912620544434
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:10.000000000Z 64.49522972106934
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:20.000000000Z 64.48652744293213
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:30.000000000Z 64.49949741363525
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:40.000000000Z 64.4949197769165
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:50.000000000Z 64.49787616729736
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
窗口化数据
使用 window() 函数 根据时间界限对您的数据进行分组。与 window() 一起传递的最常见参数是 every,它定义了窗口之间的时间长度。其他参数也可用,但在此示例中,将基数据集窗口化为一分钟窗口。
dataSet
|> window(every: 1m)
every 参数支持所有 有效的时间长度单位,包括 日历月份(1mo) 和 年份(1y)。
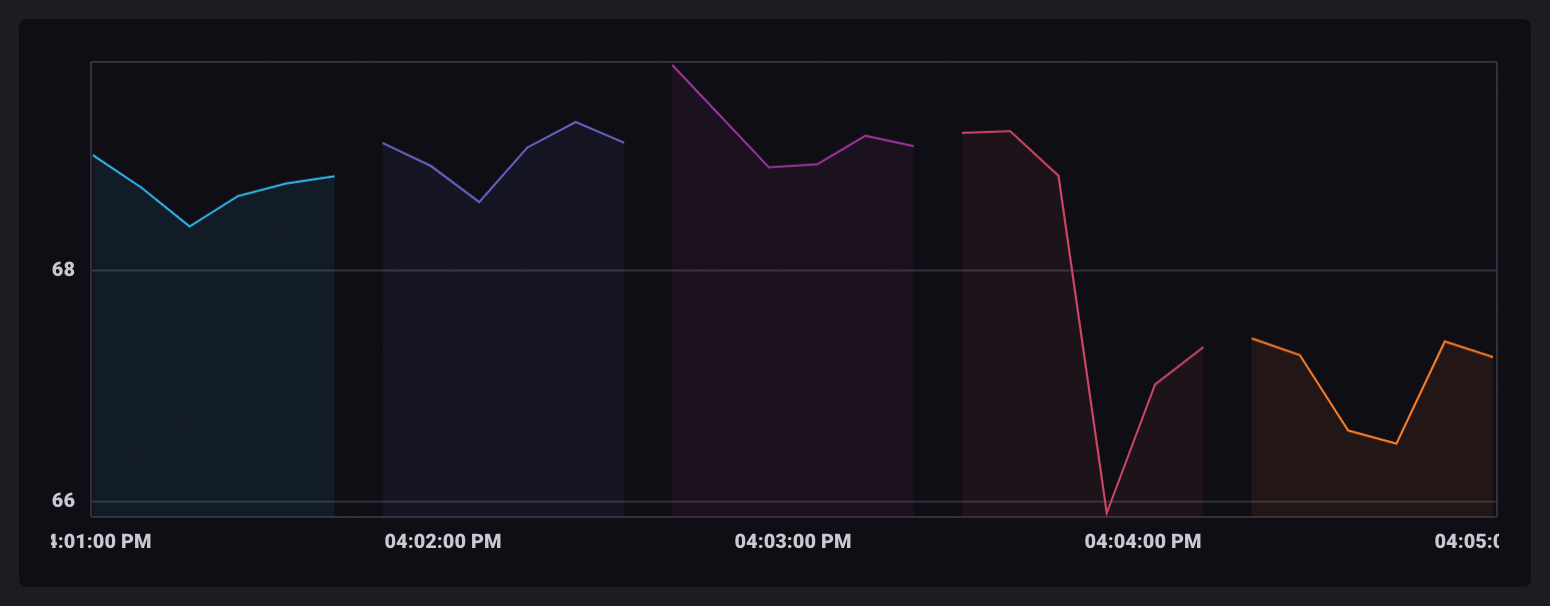
每个时间窗口输出在其自己的表中,包含所有在该窗口内记录的所有记录。
window() 输出表
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:00.000000000Z 71.11611366271973
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:10.000000000Z 67.39630699157715
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:20.000000000Z 64.16666507720947
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:30.000000000Z 64.19951915740967
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:40.000000000Z 64.2122745513916
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:50:50.000000000Z 64.22209739685059
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 64.6336555480957
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:10.000000000Z 64.16516304016113
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:20.000000000Z 64.18349742889404
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:30.000000000Z 64.20474052429199
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:40.000000000Z 68.65062713623047
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:51:50.000000000Z 67.20139980316162
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 70.9143877029419
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:10.000000000Z 64.14549350738525
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:20.000000000Z 64.15379047393799
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:30.000000000Z 64.1592264175415
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:40.000000000Z 64.18190002441406
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:52:50.000000000Z 64.28837776184082
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 64.29731845855713
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:10.000000000Z 64.36963081359863
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:20.000000000Z 64.37397003173828
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:30.000000000Z 64.44413661956787
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:40.000000000Z 64.42906856536865
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:53:50.000000000Z 64.44573402404785
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.48912620544434
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:10.000000000Z 64.49522972106934
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:20.000000000Z 64.48652744293213
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:30.000000000Z 64.49949741363525
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:40.000000000Z 64.4949197769165
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:50.000000000Z 64.49787616729736
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:55:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
在 InfluxDB UI 中可视化时,每个窗口表以不同的颜色显示。
聚合数据
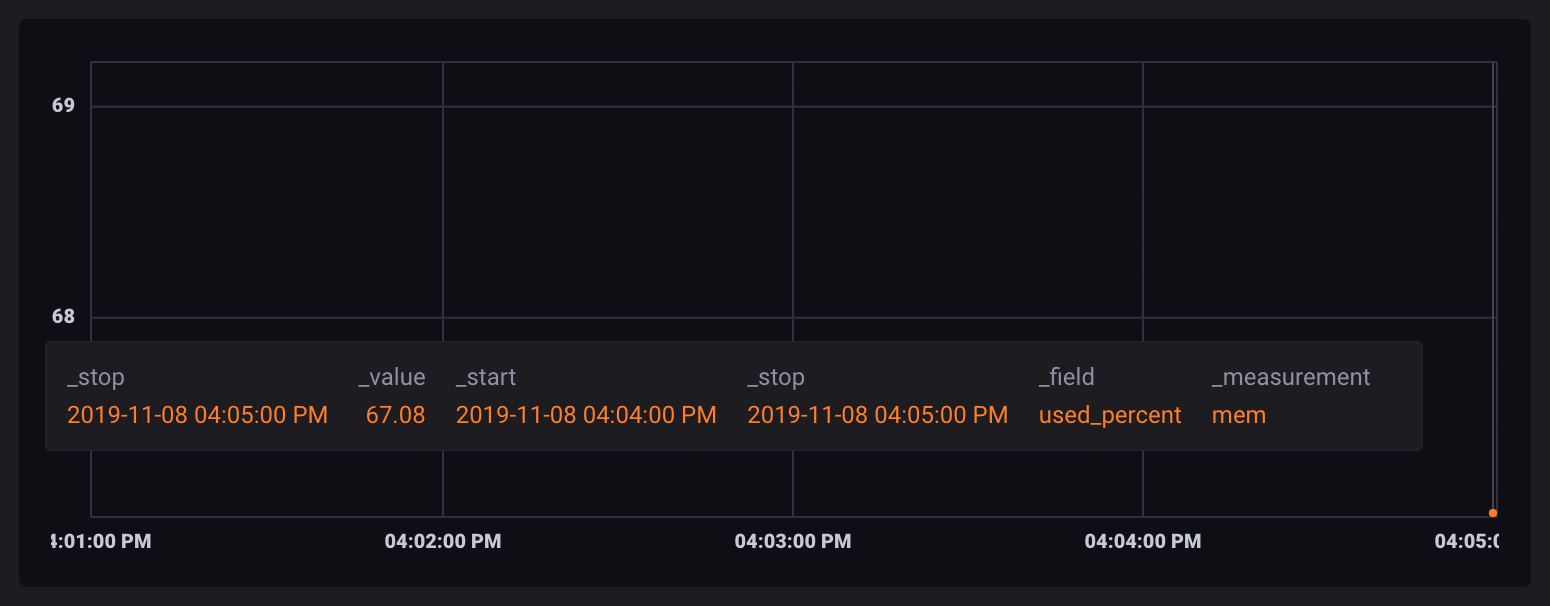
聚合函数 会取表中所有行的值,并使用它们执行聚合操作。结果以单行表中的新值输出。
由于窗口数据被分割成单独的表,聚合操作是针对每个表单独运行的,并输出只包含聚合值的新的表。
在这个例子中,使用mean()函数来输出每个窗口的平均值。
dataSet
|> window(every: 1m)
|> mean()
mean()输出表
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 65.88549613952637
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 65.50651391347249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 65.30719598134358
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 64.39330975214641
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 64.49386278788249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ----------------------------
2018-11-03T17:55:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 64.49816226959229
因为每个数据点都包含在其自己的表中,当可视化时,它们表现为单独的、不相连的点。
重新创建时间列
注意_time列不在聚合输出表中。因为每个表中的记录都被聚合在一起,它们的时间戳不再适用,该列被从组键和表中删除。
同时注意_start和_stop列仍然存在。这些代表时间窗口的下限和上限。
许多Flux函数依赖于_time列。在聚合函数之后进一步处理数据,需要重新添加_time。使用duplicate()函数来复制_start或_stop列作为新的_time列。
dataSet
|> window(every: 1m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
duplicate()输出表
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:51:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 65.88549613952637
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:51:00.000000000Z 2018-11-03T17:52:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 65.50651391347249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:52:00.000000000Z 2018-11-03T17:53:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 65.30719598134358
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:53:00.000000000Z 2018-11-03T17:54:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.39330975214641
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:54:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49386278788249
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:55:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
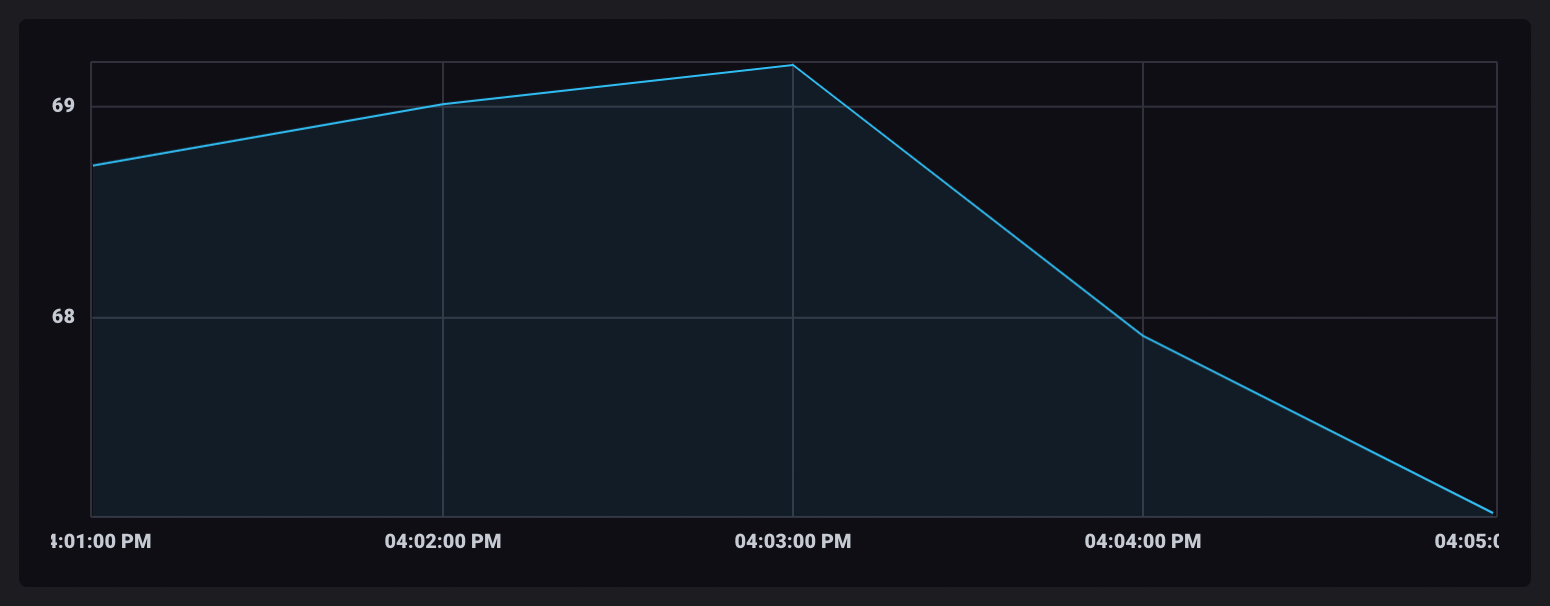
“取消窗口”聚合表
通常,将聚合值保留在单独的表中不是您想要的数据格式。使用window()函数将数据“取消窗口”到一个单个无限(inf)窗口中。
dataSet
|> window(every: 1m)
|> mean()
|> duplicate(column: "_stop", as: "_time")
|> window(every: inf)
窗口化需要一个_time列,这就是为什么在聚合后需要重新创建_time列的原因。
取消窗口的输出表
Table: keys: [_start, _stop, _field, _measurement]
_start:time _stop:time _field:string _measurement:string _time:time _value:float
------------------------------ ------------------------------ ---------------------- ---------------------- ------------------------------ ----------------------------
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:51:00.000000000Z 65.88549613952637
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:52:00.000000000Z 65.50651391347249
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:53:00.000000000Z 65.30719598134358
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:54:00.000000000Z 64.39330975214641
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49386278788249
2018-11-03T17:50:00.000000000Z 2018-11-03T17:55:00.000000000Z used_percent mem 2018-11-03T17:55:00.000000000Z 64.49816226959229
在单个表中包含聚合值,可视化中的数据点现在是相连的。
总结
您现在已创建了一个Flux查询,该查询对数据进行窗口化和聚合。本指南中概述的数据转换过程应适用于所有聚合操作。
Flux还提供了aggregateWindow()函数,该函数为您执行所有这些单独的功能。
以下Flux查询将返回相同的结果
aggregateWindow函数
dataSet
|> aggregateWindow(every: 1m, fn: mean)
这个页面有用吗?
感谢您的反馈!