
使用Grafana查询和可视化数据
使用Grafana查询和可视化InfluxDB Cloud Serverless中存储的数据。
[Grafana] 允许您查询、可视化、警报并探索您存储的指标、日志和跟踪。 [Grafana] 提供工具,将您的时序数据库(TSDB)数据转换为洞察性的图表和可视化。
安装Grafana或登录到Grafana Cloud
如果您使用的是开源版本的 Grafana,请按照 Grafana 安装说明 安装适合您的操作系统的Grafana。如果您使用 Grafana Cloud,请登录您的Grafana Cloud实例。
InfluxDB数据源
InfluxDB数据源插件包含在Grafana核心分发中。使用该插件,您可以使用InfluxQL和SQL查询并可视化存储在InfluxDB Cloud Serverless中的数据。
Grafana 10.3+
以下说明适用于 Grafana 10.3+,该版本引入了最新版本的InfluxDB核心插件。更新后的插件包括对基于InfluxDB v3的产品(如InfluxDB Cloud Serverless)的 SQL支持。
创建InfluxDB数据源
您创建哪种数据源取决于您想用于查询InfluxDB Cloud Serverless的查询语言
- 在您的Grafana用户界面(UI)中,转到 数据源。
- 单击 添加新数据源。
- 搜索并选择 InfluxDB 插件。
- 为您的数据源提供名称。
- 在 查询语言 下,选择 SQL 或 InfluxQL
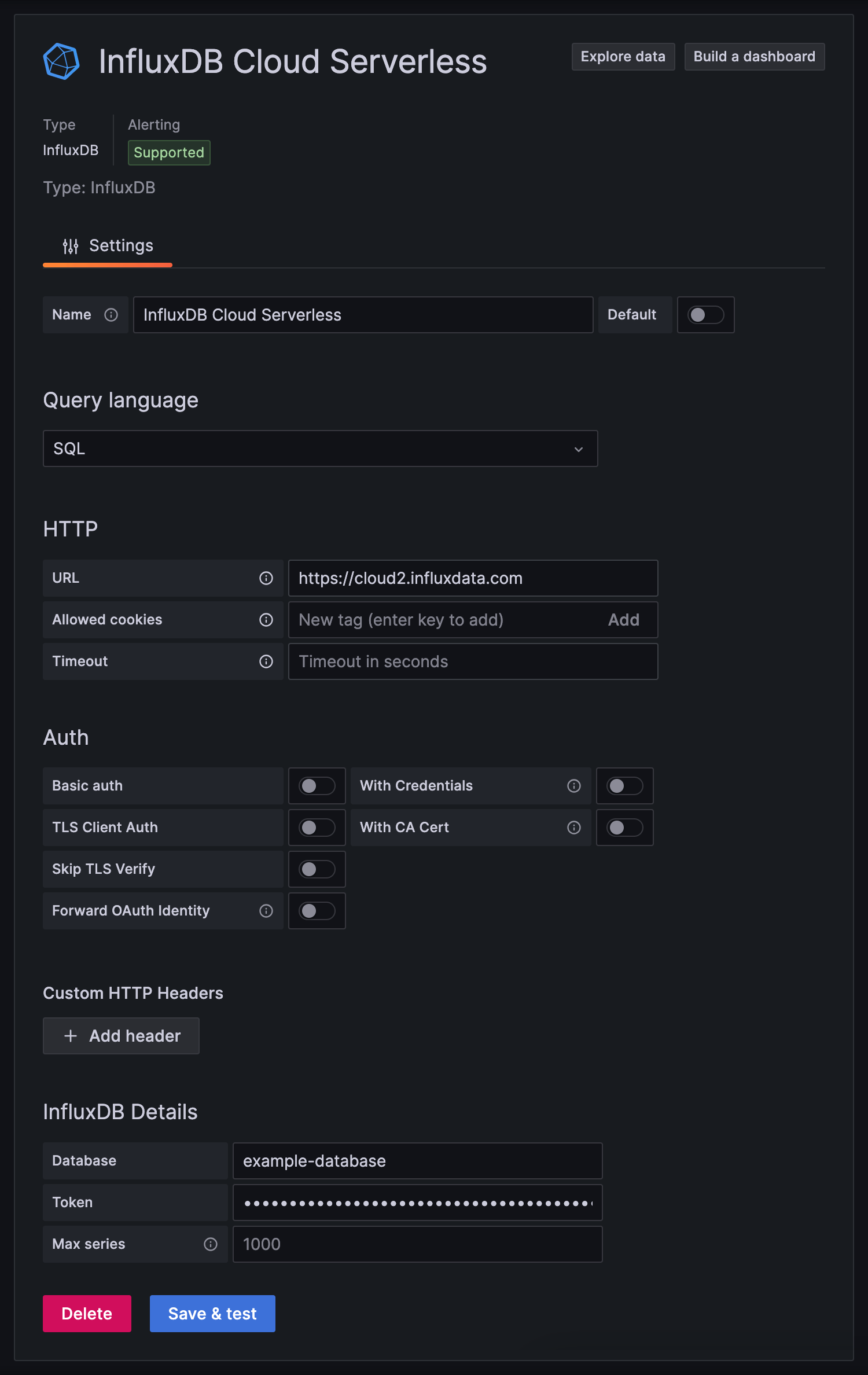
在创建使用SQL查询数据的InfluxDB数据源时
在 HTTP 下
URL:使用HTTPS协议提供您的 InfluxDB Cloud Serverless区域URL
https://cloud2.influxdata.com
在 InfluxDB详细信息 下
- 数据库:提供要查询的默认存储桶名称。在InfluxDB Cloud Serverless中,存储桶充当数据库。
- 令牌:提供具有读取您要查询的存储桶的权限的 API令牌。
单击 保存 & 测试。
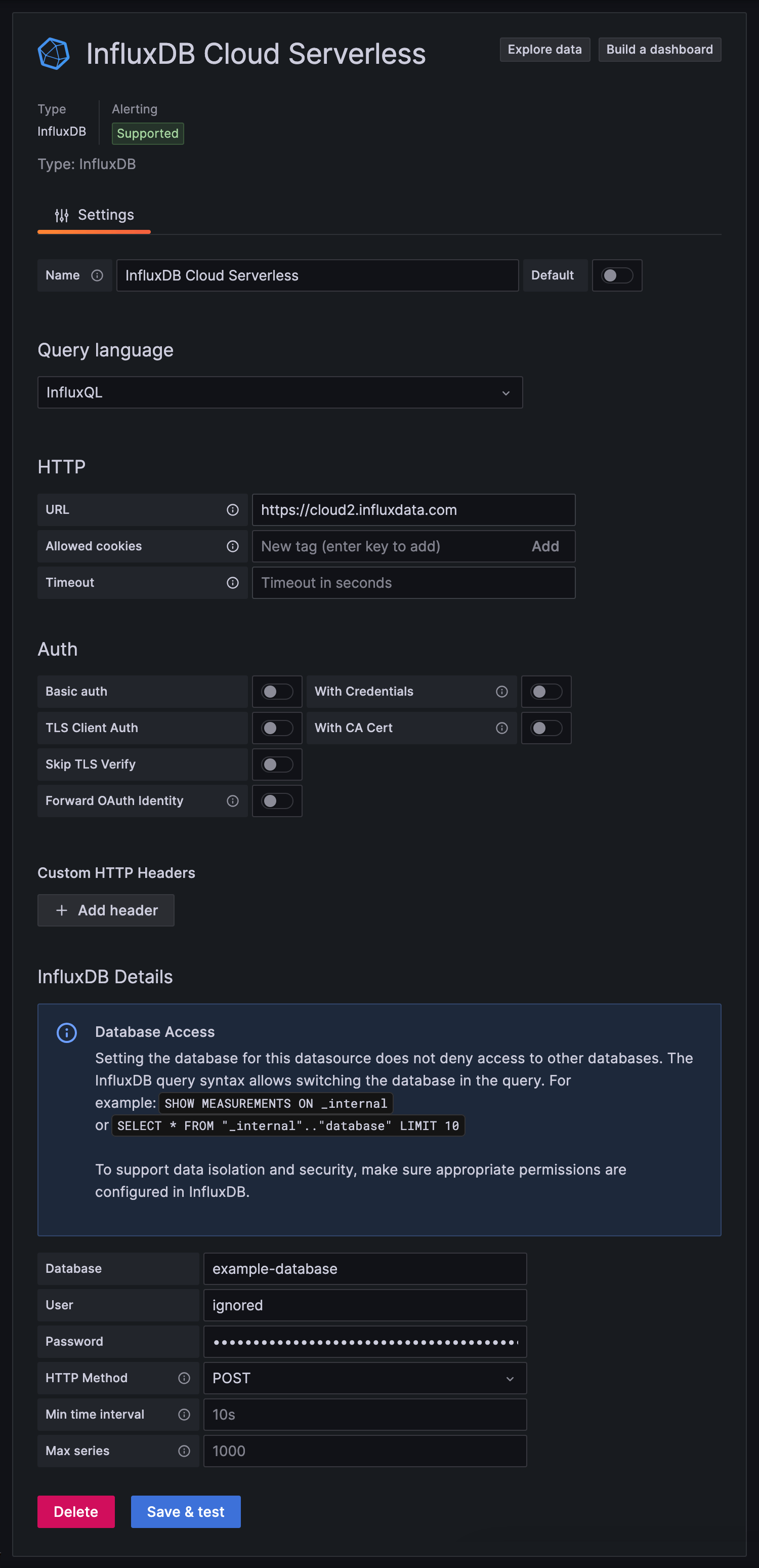
在创建使用InfluxQL查询数据的InfluxDB数据源时
将数据库和保留策略映射到存储桶
要使用InfluxQL查询InfluxDB Cloud Serverless,首先将数据库和保留策略(DBRP)组合映射到您的InfluxDB Cloud存储桶。有关更多信息,请参阅 将数据库和保留策略映射到存储桶。
在 HTTP 下
URL:使用HTTPS协议提供您的 InfluxDB Cloud Serverless区域URL
https://cloud2.influxdata.com
在 InfluxDB详细信息 下
数据库:提供要查询的数据库名称。使用映射到您的InfluxBD存储桶的数据库名称。
用户:提供任意字符串。此凭据在查询InfluxDB Cloud Serverless时被忽略,但不能为空。
密码:提供具有读取您要查询的存储桶的权限的 API令牌。
HTTP方法:选择在查询数据时使用的可用HTTP请求方法之一
- POST (推荐)
- GET
单击 保存 & 测试。
使用Grafana查询InfluxDB
配置并保存FlightSQL或InfluxDB数据源后,使用Grafana构建、运行和检查针对您的InfluxDB存储桶的查询。
在使用InfluxDB SQL实现时,一个存储桶相当于一个数据库,一个度量结构为一个表,而时间、字段和标签结构为列。要了解更多信息,请参阅查询数据。
点击探索。
在下拉菜单中,选择要查询的已保存InfluxDB数据源。
使用SQL查询表单构建您的查询
表:选择要查询的度量。
列:选择一个或多个字段和标签以作为查询结果中的列返回。
使用SQL,选择
time列以包含数据的时间戳。Grafana依赖于time列来正确图形时间序列数据。可选:切换过滤器以生成
WHERE子句语句。- WHERE:配置条件表达式以包含在
WHERE子句中。
- WHERE:配置条件表达式以包含在
可选:切换分组以生成
GROUP BY子句语句。- GROUP BY:选择要分组的列。如果您在
SELECT列表中包含聚合函数,您必须按查询的至少一个或多个列进行分组。SQL为每个组返回聚合。
- GROUP BY:选择要分组的列。如果您在
建议:切换排序以生成
ORDER BY子句语句。- ORDER BY:选择要排序的列。您可以根据时间和多个字段或标签进行排序。要按降序排序,请选择DESC。
建议:将格式更改为时间序列。
- 使用格式下拉菜单更改查询结果的格式。例如,要将查询结果可视化为一组时间序列,请选择时间序列。
点击运行查询以执行查询。
- 点击探索。
- 在下拉菜单中,选择您要查询的InfluxDB数据源。
- 使用InfluxQL查询表单构建您的查询
- FROM:选择您要查询的度量。
- WHERE:要过滤查询结果,请输入条件表达式。
- SELECT:选择要查询的字段并应用每个的聚合函数。聚合函数应用于
GROUP BY子句中定义的每个时间间隔。 - GROUP BY:默认情况下,Grafana按时间分组数据以对结果进行下采样并提高查询性能。您还可以添加其他标签以按标签进行分组。
- 点击运行查询以执行查询。
有关在Grafana中查询管理和检查的信息,请参阅Grafana Explore文档。
使用Grafana构建可视化
要全面了解如何使用Grafana创建可视化,请参阅Grafana文档。
这个页面有帮助吗?
感谢您的反馈!